Расшифровать код страницы вконтакте. Шифрование HTML кода
Эта статья - дополнение к статье про деобфускацию скриптов. Здесь будут рассмотрены основные принципы шифровки и упаковки, слабые места защит, способы ручного снятия, а также универсальные инструменты для автоматического снятия упаковщиков и навесной защиты со скриптов JavaScript. В последнее время все чаще исходный код скриптов шифруется или пакуется. Этим начали увлекаться Яндекс, DLE и другие популярные проекты, а красивые байки про "заботу о пользователях", "экономию трафика" и прочую чушь выглядят очень смешно. Что ж, если кому-то есть что скрывать, значит наша задача вывести их на чистую воду.
Начнем с теории. Из-за особенностей выполнения JavaScript все шифровщики и упаковщики, несмотря на их разнообразие, имеют всего два варианта алгоритма:или как вариант:Второй способ чаще всего используется для защиты исходного html-кода страницы, а также разными троянами для внедрения в страницу вредоносного кода, например скрытого фрейма. Оба алгоритма могут комбинироваться, "навороченность" и запутанность расшифровщика может быть любой, неизменным остается только сам принцип.
В обеих случаях получается, что функциям eval() и document.write() передаются полностью расшифрованные данные. Как их перехватить? Попробуйте заменить eval() на alert() , и в открывшемся MessageBox"е вы сразу увидите расшифрованный текст. Некоторые браузеры позволяют копировать текст из MessageBox"ов, но лучше воспользоваться таким вот полуавтоматическим декодером:
Для примера возьмем какой-нибудь скрипт с Яндекса, посмотрев исходный код видим что-то нездоровое:
Eval(function(p,a,c,k,e,r){e=function(c){return(c35?String.fromCharCode(c+29):c.toString(36))};if(!
"".replace(/^/,String)){while(c--)r=k[c]||e(c);k=}];e=function(){return"\w+"};c=1};while(c--)if(k[c])
p=p.replace(new RegExp("\b"+e(c)+"\b","g"),k[c]);return p}("$.1e
.18=8(j){3 k=j["6-9"]||"#6-9";3 l=j["6-L"]||".u-L";3 m=j["6-L-17"]
||"";3 n=j["1d"]||0;$(5).2(".6-9").14("7");$(5).2(".6-9").Z("7",8(
){3 a=$(5).x();3 o=$(5).x();3 h=$(5).B("C");$(5).v("g-4");$(5).16(
$(k).q());3 t=$(o).2("15");3 c=$(o).2(".b-r");3 d=$(o).2(".b-12");
[остальной такой же бред отрезан]
Сразу скажу, что этот скрипт обработан JavaScript Compressor , его легко узнать по сигнатуре - характерному названию фукнции в начале скрипта. Копируем целиком исходный текст скрипта, заменяем первый eval на decoder , вставляем в декодер и сохраняем его как html-страничку.Открываем ее в любом браузере и видим, что в textarea сразу появился распакованный скрипт. Радоваться пока рано, в нем убраны все переносы строчек и форматирование кода. Как с этим бороться написано в статье про деобфускацию .
Второй пример. Вот html-страничка , накрытая программой HTML Protector. Это страница, демонстрирующая возможности программы, поэтому там задействованы все опции: блокировка выделения и копирования текста, запрет правой кнопки мыши, защита картинок, скрытие строки состояния, шифрование html-кода и т.д. Открываем исходный код, смотрим. В самом верху уже знакомый нам document.write и зашифрованный скрипт. Запускаем его через декодер, получаем функцию расшифровки основного содержимого:
Code (JavaScript) :
Заменяем в функции последний document.write на decoder и вставляем после нее все три оставшихся зашифрованных скрипта:
Для удобства в статье скрипты приводятся не полностью, вы же должны копировать их целиком. Открываем декодер в браузере и видим защитные скрипты, добавленные программой, и расшифрованный исходный текст страницы. Для удобства можно расшифровывать только третий скрипт, в котором содержится html-код страницы. Вот и вся защита. Как видите, ничего сложного. Аналогично снимаются и другие защиты html-страниц.
От ручной расшифровки перейдем к автоматической. Для снятия защит первого типа я немного модифицировал уже известный вам скрипт Beautify Javascript и откомпилировал его в exe-файл. Он без проблем справляется с большинством виденных мной защит и упаковщиков JavaScript.
Eval.JavaScript.Unpacker.1.1-PCL.rar (12,124 bytes)
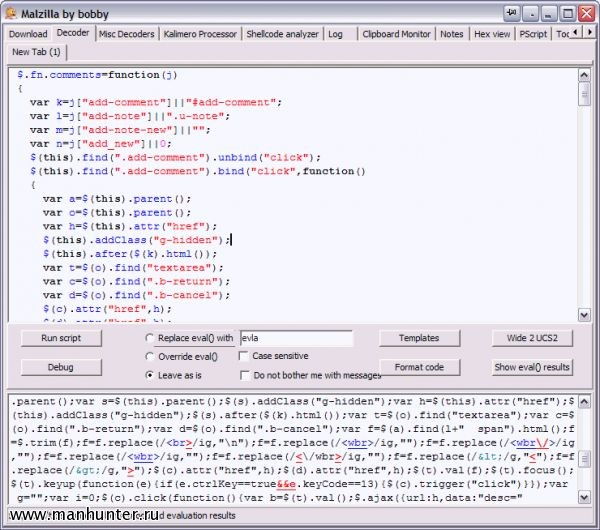
Для более сложных случаев придется пускать в ход тяжелую артиллерию. Это бесплатный проект , предназначенный для исследования троянов и другого вредоносного кода. Поскольку все программы, предназначенные для защиты авторского права, являются однозначно вредоносными, Malzilla поможет нам в борьбе с ними. Качаем (на сегодняшний день это 1.2.0), распаковываем, запускаем. Открываем вторую вкладку Decoder, в верхнее окно вставляем код зашифрованного скрипта, нажимаем кнопочку Run script .

В папке eval_temp складываются все результаты выполнения функций eval(), в том числе и промежуточные. Их можно посмотреть, нажав на кнопку Show eval() results , текст откроется в нижнем окне. Его можно скопировать, вставить в верхнее окно и сразу же отформатировать нажатием кнопки Format code . Кроме декодера Malzilla имеет еще множество инструментов и настроек, позволяющих легко снять любую защиту со скриптов JavaScript.
Также можно обратить внимание на еще один бесплатный инструмент для работы с зашифрованными скриптами - FreShow . Функций в нем поменьше, но вполне имеет место быть. С офсайта можно скачать демонстрационный ролик, показывающий пример работы с программой.
Как видите, нет ничего сложного в снятии защиты со скриптов JavaScript и с html-страниц. Вы все еще продолжаете защищать свои поганые "аффтарские права"? Тогда мы идем к вам!
1 голосДоброго времени суток, уважаемые читатели моего блога. Бывает находишь на сайте какую-нибудь красивую фишку и начинает мучать вопрос, как же создатель добился такого интересного эффекта.
Оказывается, найти ответ довольно просто. А если вы обладаете кое-какими навыками, то можете насобирать множество таких фишек и за короткое время создать свой уникальный сайт.
Сегодня мы поговорим о том, как открыть код страницы, определенного элемента и научиться использовать этот навык себе во благо.
Базовые знания о кодеМой сайт предназначен для новичков и сперва мне бы хотелось в двух словах рассказать о сайтах и коде в целом.

Чтобы необходимо нарисовать картинку, затем разрезать ее на мелкие части, написать код, благодаря которому браузер снова соберет все элементы в единое целое. Кажется, все очень сложно? Совсем нет, да и горевать по этому поводу не стоит.
Качественные сайты создаются именно так. Хотите – влезайте в это дело и изучайте, нет желания – никто не в силах вас заставить.
Скажу только одно… нет ничего более приятного, чем видеть, как непонятные слова, написанные тобой, преобразуются в единое целое и оживают: ссылки работают, кнопки шевелятся, картинки двигаются, текст ползет. Думаю, что я знаю, как чувствовал себя Виктор Франкенштейн.
Когда вы начнете постигать тайный язык и видеть, что все на самом деле значительно проще, чем казалось изначально вы не можете не верить в собственные силы и возможности мозга. Это очень круто.
Как делаются сайты? В идеале, сперва . Он просто рисует картинку. Например, как показано на рисунке ниже. Пока это всего лишь изображение, фотография. Не работают никакие ссылки, при нажатии вы никуда не переходите, поиск не осуществляется.

По этому рисунку . Посмотрите на скриншот внизу. Вам может показаться, что это нелепый и очень сложный набор символов. На самом деле все не так уж сложно, есть определенный алгоритм.
Существует всего около 150 тегов и каждый из них отвечает за определенное действие: ссылка, перенос, выделение жирным, цвет, заголовок и так далее. Разобраться в них не так уж сложно, если есть желание и не жалко времени.

Благодаря знаниям этих атрибутов можно решить практически любую задачу. Вот только пути для достижения цели каждый разработчик находит свои.
Опытные создатели сразу видят как добиться результата, а другим приходится думать, искать ответа в статьях или в исходном коде конкурентов. Они просто берут необходимую часть на стороннем сайте и редактируют под себя. Это существенно сокращает процесс работы.
Чуть позже, я покажу вам конкретный пример.
Просмотр кодаИтак, давайте я для начала покажу как действовать, если вам нужно узнать чужой html. Потом мы подробнее рассмотрим все остальные вопросы.
Самый лучший способМетод, который я опишу первым, немного сложен для новичков, но в качестве ознакомления – пойдет, читайте. Открываете страничку и нажимаете на правую клавишу мыши. Выбираете пункт «Сохранить как…»

Сохраняете веб-страницу полностью. Как можете увидеть на скриншоте, я уже все скачал заранее. Тут у нас две папки.

Здесь есть все, что необходимо. Каждый элемент. Если разбираетесь в этом, то сможете быстро получить все необходимое. Но, такая задача все чаще становится невыполнимой. Закачка не осуществляется. Что делать если запрещено копировать страницу?
Это же Гугль хромКак вы уже наверное могли заметить, я чаще всего использую Google Chrome и узнать чужой код в этом браузере проще простого. Как в принципе и в любом другом. Схема будет не то что похожая, а идентичная. Открываем страничку, код которой хотим узнать, и щелкаем в любом месте правой клавишей мыши. В появившемся окне кликаем «Посмотреть код страницы».

В новом окне откроется простыня кода, в которой довольно сложно разобраться новичку. Но, не пугайтесь раньше времени.

Если вам нужно узнать код только одного элемента, достаточно навести на него мышью и щелкнуть правой клавишей. Выбираем другую функцию хрома: «Просмотр кода элемента».
Мне, например, может быть интересно каким образом сделан логотип, при использовании картинки или языка программирования? Ведь нарисовать квадрат можно при помощи css. Многие специалисты советуют как можно больше информации прописывать кодом. А как работают на популярных сайтах?

Вот и появилась необходимая информация. Сверху html, внизу css. Это два языка. Первый отвечает за текстовую составляющую, а второй за дизайн. Если бы не было css, то вам пришлось бы каждый раз прописывать цвет, размер шрифта. Для каждой странички, это очень долго. Но если бы не было html, то у нас не было бы текстов. Грубо объяснил, но в целом, все так и есть.
Кстати, если вас заинтересовало как здесь устроен , то можете посмотреть снизу ссылку на картинку. Вот вам и ответ.

Если вы любите работать в мазиле, то все будет точно также. Открываете страничку и нажимаете на правую кнопку мыши. «Исходный код страницы» если хотите увидеть весь код целиком.

При наведении на какой-либо элемент появляется возможность открыть его код.

Здесь данные отображаются в нижней части экрана, а в остальном все точно также.

В Яндекс браузере все точно также, как и в предыдущих двух вариантах, открываем страницу, правая клавиша мыши, посмотреть код страницы.

Наводим курсор на элемент, если хотим узнать именно его код.

Отображается все тут точно также, как и в хроме.

Ну и напоследок Opera.

Кстати, возможно вы заметили, что не обязательно пользоваться мышью. Для открытия кода есть быстрое сочетание клавиш и для всех браузеров оно одинаковое: CTRL+U .

Для элементов: Ctrl+Shift+C.

Вот так выглядит результат.

А теперь смотрите как все работает. Находите вы сайт и очень вам нравится какой-то элемент. Например, вот этот. Как открыть код элемента вы уже знаете.

Теперь копируете его.

Я пользуюсь , вставляю этот код в новый html файл, в тег body (тело по-английски).

Теперь посмотрим, как это все будет выглядеть в браузере.

Готово. Чтобы текст был выровнен по краям и приобрел зеленоватый цвет нужно подключить к этому документу css и скопировать еще один код с того сайта, с которого мы тырили этот.

Сейчас я не буду этим заниматься. На это нужно больше времени: и моего, и вашего. Думаю, что все подробности я опишу в своих будущих публикациях. Подписывайтесь на рассылку и узнаете о появлении статьи первым.
Если же терпеть нет сил, а узнать больше о html и css хочется уже сейчас, то могу по традиции порекомендовать вам бесплатные обучающие курсы.
Здесь 33 урока, которые позволят освоить html — «Бесплатный курс по HTML» .

А тут полная информация о css — «Бесплатный курс по CSS (45 видеоуроков!)» .

Теперь вы знаете чуть больше. Желаю вам успехов в ваших начинаниях. До новых встреч!
В статье будут рассмотрены основные принципы шифровки
и упаковки
, слабые места защит, способы ручного снятия, а также универсальные инструменты для автоматического снятия упаковщиков и навесной защиты со скриптов JavaScript
.
В последнее время все чаще исходный код скриптов шифруется или пакуется. Этим начали увлекаться Яндекс, DLE и другие популярные проекты, а красивые байки про "заботу о пользователях", "экономию трафика" и прочую чушь выглядят очень смешно. Что ж, если кому-то есть что скрывать, значит наша задача вывести их на чистую воду.
Начнем с теории. Из-за особенностей выполнения JavaScript все шифровщики и упаковщики, несмотря на их разнообразие, имеют всего два варианта алгоритма:
Var encrypted="зашифрованные данные";
function decrypt(str) {
}
// Выполнить расшифрованный скрипт
eval(decrypt(encrypted));
или как вариант:
var encrypted="зашифрованные данные";
function decrypt(str) {
// функция расшифровки или распаковки
}
// Вывести на экран расшифрованные данные
document.write(decrypt(encrypted));
Второй способ чаще всего используется для защиты исходного html-кода страницы, а также разными троянами для внедрения в страницу вредоносного кода, например скрытого фрейма. Оба алгоритма могут комбинироваться, "навороченность" и запутанность расшифровщика может быть любой, неизменным остается только сам принцип.
В обеих случаях получается, что функциям eval() и document.write() передаются полностью расшифрованные данные. Как их перехватить? Попробуйте заменить eval() на alert() , и в открывшемся MessageBox "е вы сразу увидите расшифрованный текст. Некоторые браузеры позволяют копировать текст из MessageBox "ов, но лучше воспользоваться таким вот полуавтоматическим декодером:
JavaScript Decoder
// Функция записи в лог результатов расшифровки
function decoder(str) {
document.getElementById("decoded").value+=str+"\n";
}
Для примера возьмем какой-нибудь
скрипт с Яндекса, посмотрев исходный код видим что-то нездоровое:
eval(function(p,a,c,k,e,r){e=function(c){return(c35?String.fromCharCode(c+29):c.toString(36))};if(!
"".replace(/^/,String)){while(c--)r=k[c]||e(c);k=}];e=function(){return"\w+"};c=1};while(c--)if(k[c])
p=p.replace(new RegExp("\b"+e(c)+"\b","g"),k[c]);return p}("$.1e
.18=8(j){3 k=j["6-9"]||"#6-9";3 l=j["6-L"]||".u-L";3 m=j["6-L-17"]
||"";3 n=j["1d"]||0;$(5).2(".6-9").14("7");$(5).2(".6-9").Z("7",8(
){3 a=$(5).x();3 o=$(5).x();3 h=$(5).B("C");$(5).v("g-4");$(5).16(
$(k).q());3 t=$(o).2("15");3 c=$(o).2(".b-r");3 d=$(o).2(".b-12");
[остальной такой же бред отрезан]
Сразу скажу, что этот скрипт обработан JavaScript Compressor , его легко узнать по сигнатуре - характерному названию фукнции в начале скрипта. Копируем целиком исходный текст скрипта, заменяем первый eval на decoder , вставляем в декодер и сохраняем его как html-страничку.
// Сюда вставить зашифрованный скрипт, предварительно
// заменить в нем все вызовы eval() и document.write() на decoder().
decoder(function(p,a,c,k,e,r){e=function(c){return(cQAPKRV%22NCLEWCEG? HctcQa ...
hp_d01(unescape(">`mf{%22`eamnmp? !DDDDDD %22v ...
Для удобства в статье скрипты приводятся не полностью, вы же должны копировать их целиком. Открываем декодер в браузере и видим защитные скрипты, добавленные программой, и расшифрованный исходный текст страницы. Для удобства можно расшифровывать только третий скрипт, в котором содержится html-код страницы. Вот и вся защита. Как видите, ничего сложного. Аналогично снимаются и другие защиты html-страниц.
От ручной расшифровки перейдем к автоматической. Для снятия защит первого типа я немного модифицировал уже известный вам скрипт Beautify Javascript и откомпилировал его в exe-файл. Он без проблем справляется с большинством виденных мной защит и упаковщиков JavaScript.
Eval JavaScript Unpacker 1.1
Eval.JavaScript.Unpacker.1.1-PCL.zip
(12,073 bytes)
Для более сложных случаев придется пускать в ход тяжелую артиллерию. Это бесплатный проект Malzilla , предназначенный для исследования троянов и другого вредоносного кода. Поскольку все программы, предназначенные для защиты авторского права, являются однозначно вредоносными, Malzilla поможет нам в борьбе с ними. Качаем последнюю версию (на сегодняшний день это 1.2.0), распаковываем, запускаем. Открываем вторую вкладку Decoder, в верхнее окно вставляем код зашифрованного скрипта, нажимаем кнопочку Run script .
Функций в нем поменьше, но вполне имеет место быть. С офсайта можно скачать демонстрационный ролик, показывающий пример работы с программой.
Как видите, нет ничего сложного в снятии защиты со скриптов JavaScript и с html-страниц. Вы все еще продолжаете защищать свои поганые "аффтарские права"? Тогда мы идем к вам!
Под всеми красивыми изображениями, совершенной типографией, и чудесно размещенными призывами к действию, расположен исходный код вашего сайта.
Ежедневно, этот код ваш браузер превращает во впечатляющие страницы для ваших посетителей и клиентов.
Google и другие поисковые системы «читают» этот код, чтобы определить, где ваши веб-страницы должны появиться в их индексах для данного поискового запроса.
Следовательно, очень большое значение для поисковой оптимизации (SEO) имеет то, что находится в исходном коде.
Это краткое руководство, продемонстрирует вам, как читать исходный код вашего сайта для того, чтобы вы были уверены, в правильности SEO и чтобы научить вас проверять ваши условия SEO.
Также рассмотрим несколько других ситуаций, когда знания, как просмотреть и изучить главные части исходного кода, помогут в других маркетинговых изысканиях.
Как просмотреть исходный код.Первый шаг в проверке исходного кода вашего сайта, это посмотреть реальный исходный код. Любой веб-браузер позволяет сделать это легко.
Ниже перечислены клавиатурные команды для просмотра исходного кода вашей веб-страницы для PC и Mac .
- Firefox — CTRL + U (Удерживая нажатой клавишу CTRL, нажмите клавишу»U») Кроме того, вы можете пойти в меню «Firefox», затем нажмите » Web Developer «, а затем» Исходный код страницы «.
- Internet Explorer — CTRL + U. Или щелкните правой кнопкой мыши и выберите пункт «View Source».
- Хром — CTRL + U. Вы можете нажать на изображение ключа с тремя горизонтальными линиями в правом верхнем углу. Затем нажмите на «Инструменты» и выберите «View Source».
- Опера — CTRL + U. Вы также можете щелкнуть правой кнопкой на веб-странице и выбрать «Просмотр исходного кода страницы.»
Макинтош
- Safari — сочетание клавиш Option + Command + U. Вы также можете щелкнуть правой кнопкой на веб-странице и выберите «Показать Page Source».
- Firefox — Вы можете щелкнуть правой кнопкой и выберите пункт «исходный текст» или вы можете перемещаться в меню «Сервис», выберите «Web Developer», и нажмите «Page Source.» Сочетание клавиш Ctrl + U.
- Хром — Перейдите в «Вид», затем нажмите «разработчик», а затем «View Source». Вы также можете щелкнуть правой кнопкой и выберать пункт «Просмотр исходного кода страницы.» Сочетание клавиш Option + Command + U.
После того, как вы знаете, как просмотреть исходный код, вы должны знать, как осуществить поиск в нем.
Как правило, одни и те же функции поиска, которые вы используете при нормальном просмотре веб-страниц, применяются и к поиску в исходном коде.
Команды, CTRL + F (найти) поможет Вам быстро просмотреть исходный код важных элементов SEO.
Теги заголовков.Тег заголовка является самым главным элементом SEO. Это самое главное в исходном коде.
Если вы собираетесь взять одну лишь ценную вещь из этой статьи, обратите внимание на это:
Вы знаете, эти результаты Google предоставляет, когда вы ищете что-то.
Все эти результаты берутся из тегов заголовков веб-страниц. Так что, если у вас нет тегов заголовков в исходном коде, вы можете не появиться в Google (или в любой другой поисковой системе).
Верите или нет, я на самом деле видел веб-сайты без тегов заголовков. Давайте попробуем сделать быстрый поиск в Google для термина «Marketing Guides
«. Что мы видим: 
Вы можете видеть, первый результат поиска для блога KISSmetrics раздел Marketing Guides .
Если мы перейдем по ссылке первого результата поиска и просмотрим исходный код страницы, то можно увидеть в заголовке тег: 
Тег заголовка обозначается открывающим тегом: . и заканчивается закрывающим тегом: . Тег заголовка, расположен как правило, в верхней части исходного кода в разделе .
И мы видим, что содержание внутри тега заголовка соответствует тому, что используется в заголовке результата поиска Google.
Но не только теги заголовков необходимы для того чтобы быть включенными в результаты поиска Google.
Google еще и идентифицирует слова в тегах заголовков в качестве важных ключевых слов, которые, по его мнению актуальны для поиска пользователей.
Так что если вы хотите получить определенное ранжирование веб-страницы для конкретной темы, то вам лучше убедиться, что слова, которые описывают предмет включены в тег заголовок.
Существует целый ряд онлайновых ресурсов, где вы можете узнать больше о том, как ключевые слова и теги заголовков играют важную роль в общей архитектуре вашего сайта.
Вот некоторые важные пункты, которые позволят вам помнить о важности ваших Тег заголовков:
- Убедитесь, что у вас есть только один тег заголовка на веб-страницу.
- Убедитесь в том, что каждая веб-страница на сайте имеет свой тег заголовок.
- Убедитесь, что каждый тег заголовок на сайте уникален. Никогда не дублируйте контент определенного тега заголовка.
Следующий важный элемент головной части вашей веб-страницы является мета-тег описания.
Это фрагмент вашего контента из 160 символов, который отображается под вашим заголовком в поисковых системах.

Я видел сотни сайтов, которые полностью игнорируют этот тег. Его очень легко найти в исходном коде:

Таким образом, проверьте и убедитесь, что этот тег присутствует на всех веб-страницах вашего сайта. Что еще более важно, убедитесь, что вы не дублируете его на нескольких страницах.
Дублирование мета-тег описания не пинальти для поисковой системы, но это очень большая маркетинговая ошибка.
Многие игнорируют мета тег описания, но вы действительно должны поработать в этом направлении, потому что он считывается поисковой системой.
Подумайте о том, что мета-тег описания будет помощью привлечь больше посетителей и увеличить целевые переходы на сайт.
Ctrl + U Как посмотреть исходный код элемента?Нажмите правую кнопку мыши на интересующем элементе страницы.
Google Chrome : “Просмотр кода элемента”
Opera : “Проинспектировать элемент”

FireFox : “Анализировать элемент”

В других браузерах ищите подобный по смыслу пункт меню.
Всем привет!
Специально вначале статьи выложил всю суть, для тех, кто ищет быстрый ответ.
Информация может быть многим известна, но поскольку пишу для начинающих блоггеров, веб-программистов и прочих старателей, то эта справочная статья обязательно должна присутствовать.
В будущем вы обязательно будете изучать исходный код страниц и отдельных элементов.
Давайте посмотрим на конкретном примере как можно использовать просмотр исходного кода страницы.
Например, мы хотим посмотреть какие ключевые слова (keywords) используются для конкретной страницы. Заходим на интересующую нас веб-страницу и нажимаем Ctrl+U . В отдельном окне или в отдельной закладке откроется исходный код данной страницы. Нажимаем Ctrl+F для поиска фрагмента кода. В данном случае печатаем в окне поиска слово “keywords”. Вас автоматически перебросит на фрагмент кода с этим мета-тегом и выделит искомое слово.
По аналогии можно искать и изучать другие фрагменты кода.
Просмотр всего исходного кода страницы в большинстве случаев не очень удобен, поэтому во всех браузерах существует возможность просмотреть код отдельного элемента или фрагмента.
Давайте применим на конкретном примере просмотр кода элемента. Например, посмотрим есть ли у ссылки атрибут nofollow . Нажимаем правой кнопкой мыши на интересующей нас ссылке и в выпадающем контекстном меню левой кнопкой кликаем по пункту “Просмотр кода элемента” или подобному (в зависимости от вашего браузера). Внизу, в специальном окне для анализа кода, получаем нечто подобное.
Мы видим, что в коде ссылки присутствует rel=”nofollow” . Это значит, что по этой ссылке не будет “утекать” и PR. Об этом подробней поговорим в следующих статьях. Сейчас же важно то, что вы теперь знаете как посмотреть исходный код страницы и исходный код отдельного элемента.