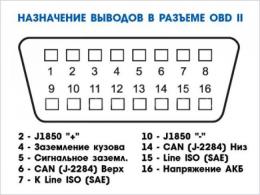
Создать файл robots txt wordpress. Правильная настройка для плагина WooCommerce
Всем привет! Сегодня статья о том, каким должен быть правильный файл robots.txt для WordPress. С функциями и предназначением мы разбирались несколько дней назад, а сейчас разберём конкретный пример для ВордПресс.
С помощью этого файла у нас есть возможность задать основные правила индексации для различных поисковых систем, а также назначить права доступа для отдельных поисковых ботов. На примере я разберу как составить правильный robots.txt для WordPress. За основу возьму две основные поисковые системы — Яндекс и Google.
В узких кругах вебмастеров можно столкнуться с мнением, что для Яндекса необходимо составлять отдельную секцию, обращаясь к нему по User-agent: Yandex . Давайте вместе разберёмся, на чём основаны эти убеждения.
Яндекс поддерживает директивы Clean-param и Host , о которых Google ничего не знает и не использует при обходе.
Разумно использовать их только для Yandex, но есть нюанс — это межсекционные директивы, которые допустимо размещать в любом месте файла, а Гугл просто не станет их учитывать. В таком случае, если правила индексации совпадают для обеих поисковых систем, то вполне достаточно использовать User-agent: * для всех поисковых роботов.
При обращении к роботам по User-agent важно помнить, что чтение и обработка файла происходит сверху вниз, поэтому используя User-agent: Yandex или User-agent: Googlebot необходимо размещать эти секции в начале файла.
Пример Robots.txt для WordPress
Сразу хочу предупредить: не существует идеального файла, который подойдет абсолютно всем сайтам, работающим на ВордПресс! Не идите на поводу, слепо копируя содержимое файла без проведения анализа под ваш конкретный случай! Многое зависит от выбранных настроек постоянных ссылок, структуры сайта и даже установленных плагинов. Я рассматриваю пример, когда используется ЧПУ и постоянные ссылки вида /%postname%/ .

Как и любая система управления контентом, имеет свои административные ресурсы, каталоги администрирования и прочее, что не должно попасть в индекс поисковых систем. Для защиты таких страниц от доступа необходимо запретить их индексацию в данном файле следующими строками:
Disallow: /cgi-bin Disallow: /wp-
Директива во второй строке закроет доступ по всем каталогам, начинающимся на /wp- , в их число входят:
- wp-admin
- wp-content
- wp-includes
Но мы знаем, что изображения по умолчанию загружаются в папку uploads , которая находится внутри каталога wp-content . Разрешим их индексацию строкой:
Allow : */uploadsСлужебные файлы закрыли, переходим к исключению дублей с основным содержимым, которые снижают в пределах одного домена и увеличивают вероятность наложения на сайт фильтра со стороны ПС. К дублям относятся страницы категорий, авторов, тегов, RSS-фидов, а также постраничная навигация, трекбеки и отдельные страницы с комментариями. Обязательно запрещаем их индексацию:
Disallow: /category/ Disallow: /author/ Disallow: /page/ Disallow: /tag/ Disallow: */feed/ Disallow: */trackback Disallow: */comments
Далее хотелось бы уделить особое внимание такому аспекту как . Если вы используете ЧПУ, то страницы содержащие в URL знаки вопроса зачастую являются «лишними» и опять же дублируют основной контент. Такие страницы с параметрами следует запрещать аналогичным образом:
Disallow: */?
Это правило распространяется на простые постоянные ссылки?p=1 , страницы с поисковыми запросами?s= и другими параметрами. Ещё одной проблемой могут стать страницы архивов, содержащие в URL год, месяц. На самом деле их очень просто закрыть, используя маску 20* , тем самым запрещая индексирование архивов по годам:
Disallow: /20*
Для ускорения и полноты индексации добавим путь к расположению . Робот обработает файл и при следующем посещении сайта будет его использовать для приоритетного обхода страниц.
Sitemap: https://сайт/sitemap.xml
В файле robots.txt можно разместить дополнительную информацию для роботов, повышающую качество индексации. Среди них директива Host — указывает на для Яндекса:
Host : webliberty .ruПри работе сайта по HTTPS необходимо указать протокол:
Host: https://сайт
С 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Подводя итог, я объединил всё выше сказанное воедино и получил содержимое файла robots.txt для WordPress, который использую уже несколько лет и при этом в индексе нет дублей:
User-agent: * Disallow: /cgi-bin Disallow: /wp- Disallow: /category/ Disallow: /author/ Disallow: /page/ Disallow: /tag/ Disallow: */feed/ Disallow: /20 * Disallow: */trackback Disallow: */comments Disallow: */? Allow: */uploads Sitemap: https://сайт/sitemap.xml
Постоянно следите за ходом индексации и вовремя корректируйте файл в случае появления дублей.
От того правильно или нет составлен файл зависит очень многое, поэтому обратите особо пристальное внимание к его составлению, чтобы поисковики быстро и качественно индексировали сайт. Если у вас возникли вопросы — задавайте, с удовольствием отвечу!
Здравствуйте, дорогие читатели! С вами проект «Анатомия Бизнеса» и вебмастер Александр. Мы продолжаем цикл статей мануала «Как создать сайт на WordPress и заработать на нем», и сегодня мы поговорим о том, как создать файл robots.txt для WordPress и зачем нужен данный файл.
В прошлых 16-и уроках мы рассмотрели огромное количество материала. Наш сайт практически готов для того, чтобы начать заполнять его интересным контентом и проводить SEO-оптимизацию.
Итак, давайте перейдем к делу!
Для чего сайту нужен файл robots.txt?
Основную ценность на нашем сайте будет представляет именно контент, но помимо него на сайте есть целая куча технических разделов или страниц, которые для поискового робота не является чем-то ценным.
К таким разделам можно отнести:
— админ. панель
— поиск
— возможно, Вы захотите закрыть от индексации комментарии
— или какие-то страницы-дубли, имеющие в своих урлах одни и те же символы
В общем, robots.txt предназначен для того, чтобы запретить поисковому роботу индексацию тех или иных страниц.
В свое время в понимания того, как работает robots txt, мне очень помогла эта картинка:
Как мы можем видеть, первым делом, когда поисковый робот заходит на сайт, он ищет именно этот Файл! После его анализа он понимает в какие директории ему нужно заходить, а в какие нет.
Многие начинающие веб мастера пренебрегают данным файлом, а зря! Т. к. от того насколько «чистой» будет индексация вашего сайта, зависит его позиции в поисковике.
Пример написания файла robots.txt для WordPress
Давайте теперь разбираться, как писать данный файл. Тут нет ничего сложного, для его написания нам достаточно открыть обычный текстовый редактор «блокнот» или можно воспользоваться профессиональным редактором типа notepad+.
Вводим в редактор следующие данные:
User-agent: Yandex
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-comments
Disallow: /wp-content/themes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: */trackback
Disallow: */feed
Disallow: /cgi-bin
Disallow: *?s=
Host: site.ruUser-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-comments
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: */trackback
Disallow: */feed
Disallow: /cgi-bin
Disallow: *?s=Sitemap: http://site.ru/sitemap.xml
А теперь давайте разбираться со всем этим.
Первое, на что нужно обратить внимание, так это на то, что файл разбит на два больших блока.
И в начале каждого блока стоит директория «User-agent», которая указывает для какого робота сделан данный блок.
У нас первый блок сделан для роботов Yandex, о чем свидетельствует данная строка: «User-agent: Yandex»
Второй блок говорит о том, что он для всех остальных роботов. На это указывает звездочка «User-agent: *».
Директория «Disallow» устанавливает, какие именно разделы запрещены к индексации.
Теперь разберем по разделам:
/wp-admin - запрет на индексацию админ. панели
/wp-includes - запрет на индексацию системных папок движка WordPress
/wp-comments - запрет на индексацию комментариев
/wp-content/plugins - запрет на индексацию папки с плагинами для WordPress
/wp-content/themes - запрет на индексацию папки с темами для WordPress
/wp-login.php - запрет на индекс формы входа на сайт
/wp-register.php - закрываем от робота форму регистрации
*/feed - запрет на индекс RSS-фида блога
/cgi-bin - запрет на индекс каталога скриптов на сервере
*?s= — запрет на индексацию всех URL, которые содержат?s=
И в самом конце robots.txt показываем роботу, где находится файл sitemap.xml
Sitemap: http://site.ru/sitemap.xml
После того как файл готов, сохраняем его в корневой директории сайта.
Как закрыть какие-то рубрики от индексации?
Например, Вы не хотите показывать какую-то рубрику на Вашем сайте для поисковых роботов. Причины на это могут быть совершенно разные. Например, Вы хотите, чтобы Ваш личный дневник читали только постоянные посетители сайта.
Первое, что нам нужно сделать, — это узнать URL данной рубрики. Скорее всего, он будет /moy-dnevnik.
Для того чтобы закрыть данную рубрику, нам достаточно добавить в нее следующую строку: Disallow: /moy-dnevnik
Robots.txt - когда ждать эффект?
Могу сказать из личной практики, что не стоит ожидать, что уже при следующем апдейте все закрытые Вами рубрики уйдут из индекса. Иногда этот процесс может занимать до двух месяцев. Просто запаситесь терпением.
Также необходимо учитывать, что роботы Google могут просто игнорировать данный файл, если сочтут, что страница уж очень уникальная и интересная.
О чем нужно помнить ВСЕГДА!
Конечно, техническая составляющая является не маловажной, но в первую очередь нужно делать акцент на полезный и интересный контент, за которым будут возвращаться постоянные читатели Вашего проекта! Именно ставка на качество сделает Ваш ресурс востребованным и популярным
Успехов Вам в интернет-бизнесе
Robots.txt создан для регулирования поведения поисковых роботов на сайтах, а именно куда им заходить можно и брать в поиск, а куда нельзя. Лет 10 назад сила данного файла была велика, по его правилам работали все поисковые системы, но сейчас он скорее как рекомендация, чем правило.
Но пока не отменили, вебмастера должны делать его и настраивать правильно исходя из структуры и иерархии сайтов. Отдельная тема это WordPress, потому что CMS содержит множество элементов, которые не нужно сканировать и отдавать в индекс. Разберемся как правильно составить robots.txt
Где лежит файл robots в WordPress
На любом из ресурсов robots.txt должен лежать в корневой папке. В случае с вордпресс, там где находится папка wp-admin и ей подобные.
Расположение на сервере
Если не создавался и не загружался администратором сайта, то по умолчанию на сервере не найти. Стандартная сборка WordPress не предусматривает наличие такого объекта.
Как создать правильный robots txt
Создать правильный robots txt задача не трудная, сложнее прописать в нем правильные директивы. Сначала создадим документ, открываем программу блокнот и нажимаем сохранить как.
 Сохраняем документ
Сохраняем документ В следующем окне задаем название robots, оставляем расширение txt, кодировку ANSI и нажимаем сохранить. Объект появится в папке куда произошло сохранение. Пока документ пустой и ничего не содержит в себе, давайте разберемся какие именно директивы он может поддерживать.
При желании можете сразу скачать его на сервер в корень через .
 Сохранение роботса
Сохранение роботса Настройка команд
Выделю четыре основные команды:
- User-agent: показывает правила для разных поисковых роботов, либо для всех, либо для отдельных
- Disalow: запрещает доступ
- Allow: разрешаем доступ
- Sitemap: адрес до XML карты
Устаревшие и ненужные конфигурации:
- Host: указывает главное зеркало, стало не нужным, потому что поиск сам определит правильный вариант
- Crawl-delay: ограничивает время на пребывание робота на странице, сейчас сервера мощные и беспокоится о производительности не нужно
- Clean-param: ограничивает загрузку дублирующегося контента, прописать можно, но толку не будет, поисковик проиндексирует все, что есть на сайте и возьмет по–максимому страниц
Рабочий пример инструкций для WordPress
Дело в том что поисковой робот не любит запрещающие директивы, и все равно возьмет в оборот, что ему нужно. Запрет на индексацию должен быть объектов, которые 100% не должны быть в поиске и в базе Яндекса и Гугла. Данный рабочий пример кода помещаем в robots txt.
User-agent: * Disallow: /wp- Disallow: /tag/ Disallow: */trackback Disallow: */page Disallow: /author/* Disallow: /template.html Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://ваш домен/sitemap.xml
Разберемся с текстом и посмотрим что именно мы разрешили, а что запретили:
- User-agent, поставили знак *, тем самым сообщив что все поисковые машины должны подчиняться правилам
- Блок с Disallow запрещает к индексу все технические страницы и дубли. обратите внимание что я заблокировал папки начинающиеся на wp-
- Блок Allow разрешает сканировать скрипты, картинки и css файлы, это необходимо для правильного представления проекта в поиске иначе вы получите портянку без оформления
- : показывает путь до XML карты сайта, обязательно нужно ее сделать, а так же заменить надпись”ваш домен”
Остальные директивы рекомендую не вносить, после сохранения и внесения правок, загружаем стандартный robots txt в корень WordPress. Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так.
 Адрес в строке запроса
Адрес в строке запроса Как проверить работу robots.txt
Стандартный способ проверить через сервис yandex webmaster . Для лучшего анализа нужно зарегистрировать и установить на сайт сервис. Вверху видим загрузившийся robots, нажимаем проверить.
 Проверка документа в yandex
Проверка документа в yandex Ниже появится блок с ошибками, если их нет то переходим к следующему шагу, если неверно отображается команда, то исправляем и снова проверяем.
 Отсутствие ошибок в валидаторе
Отсутствие ошибок в валидаторе Проверим правильно ли Яндекс обрабатывает команды, спускаемся чуть ниже, введем два запрещенных и разрешенных адреса, не забываем нажать проверить. На снимке видим что инструкция сработала, красным помечено что вход запрещен, а зеленой галочкой, что индексирование записей разрешена.
 Проверка папок и страниц в яндексе
Проверка папок и страниц в яндексе Проверили, все срабатывает, перейдем к следующему способу это настройка robots с помощью плагинов. Если процесс не понятен, то смотрите наше видео.
Плагин–генератор Virtual Robots.txt
Если не хочется связываться с FTP подключением, то приходит на помощь один отличный WordPress плагин–генератор называется Virtual Robots.txt . Устанавливаем стандартно из админки вордпресс поиском или загрузкой архива, выглядит так.
 Как выглядит Virtual Robots.txt
Как выглядит Virtual Robots.txt Настройки > Virtual Robots.txt, видим знакомую конфигурацию, но нам нужно ее заменить, на нашу из статьи. Копируем и вставляем, не забываем сохранять.
 Настройка Virtual Robots.txt
Настройка Virtual Robots.txt Роботс автоматически создастся и станет доступен по тому же адресу. При желании проверить есть он в файлах WordPress – ничего не увидим, потому что документ виртуальный и редактировать можно только из плагина, но Yandex и Google он будет виден.
Добавить с помощью Yoast SEO
Знаменитый плагин Yoast SEO предоставляет возможность добавить и изменить robots.txt из панели WordPress. Причем созданный файл появляется на сервере (а не виртуально) и находится в корне сайта, то есть после удаления или деактивации роботс остается. Переходим в Инструменты > Редактор.
 Yoast SEO редактор файлов
Yoast SEO редактор файлов Если robots есть, то отобразится на странице, если нет есть кнопка “создать”, нажимаем на нее.
 Кнопка создания robots
Кнопка создания robots Выйдет текстовая область, записываем, имеющийся текст из универсальной конфигурации и сохраняем. Можно проверить по FTP соединению документ появится.
Изменить модулем в All in One SEO
Старый плагин All in One SEO умеет изменять robots txt, чтобы активировать возможность переходим в раздел модули и находим одноименный пункт, нажимаем Activate.
 Модули в All In one Seo
Модули в All In one Seo В меню All in One SEO появится новый раздел, заходим, видим функционал конструктора.
 Работа в модуле AIOS
Работа в модуле AIOS - Записываем имя агента, в нашем случае * или оставляем пустым
- Разрешаем или запрещаем индексацию
- Директория или страница куда не нужно идти
- Результат
Модуль не удобный, создать по такому принципу валидный и корректный robots.txt трудно. Лучше используйте другие инструменты.
Правильная настройка для плагина WooCommerce
Чтобы сделать правильную настройку для плагина интернет магазина на WordPress WooCommerce, добавьте эти строки к остальным:
Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=*
Делаем аналогичные действия и загружаем на сервер через FTP или плагином.
Итог
Подведем итог что нужно сделать чтобы на сайте WordPress был корректный файл для поисковиков:
- Создаем вручную или с помощью плагина файл
- Записываем в него инструкции из статьи
- Загружаем на сервер
- Проверяем в валидаторе Yandex
- Не пользуйтесь генераторами robots txt в интернете, пошевелите немного руками
Совершенствуйте свои блоги на WordPress, продвигайтесь и правильно настраивайте все параметры, а мы в этом поможем, успехов!
От автора: одним из файлов, которые используют поисковики при индексации вашего сайта, есть файл robots.txt. Не сложно понять из названия файла, что он используется для роботов. И действительно, этот файл позволяет указать поисковому роботу что можно индексировать на вашем сайте, а что вы не хотите видеть в поисковом индексе. Итак, давайте посмотрим, как настроить robots txt для сайта WordPress.
Статей на эту тему в сети множество. Практически в каждой из этих статей можно найти свой вариант файла robots txt, который можно взять и использовать практически без правок на своем сайте WordPress. Я не буду в очередной раз переписывать в данной статье один из таких вариантов, поскольку особого смысла в этом нет — все эти варианты вы без труда сможете найти в сети. В этой же статье мы просто разберем, как как создать robots txt для WordPress и какой минимум правил там должен быть.
Начнем с того, где должен располагаться файл robots.txt и что в него писать. Данный файл, как и файл sitemap.xml, должен быть расположен в корне вашего сайта, т.е. он должен быть доступен по адресу http://site/robots.txt
Попробуйте обратиться по такому адресу, заменив слово site адресом вашего сайта. Вы можете увидеть при этом примерно такую картину:

Хотя можете увидеть и вот такую картину:

Странная ситуация — скажете вы. Действительно, адрес один и тот же, но в первом случае файл доступен, во втором — нет. При этом если заглянуть в корень сайта, то никакого файла robots.txt вы там не обнаружите. Как так и где же находится robots.txt в WordPress?
Все дело в простой настройке — это настройка ЧПУ. Если на вашем сайте включены ЧПУ, тогда вы увидите динамически сгенерированный движком robots.txt. В противном случае будет возвращена ошибка 404.
Включим ЧПУ в меню Настройки — Постоянные ссылки, отметив настройку Название записи. Сохраним изменения — теперь файл robots.txt будет динамически генерироваться движком.
Как видно на первом рисунке, в этом файле используются некие директивы, задающие определенные правила, а именно — разрешить или запретить индексировать что-либо по заданному адресу. Как несложно догадаться, директива Disallow запрещает индексирование. В данном случае это все содержимое папки wp-admin. Ну а директива Allow разрешает индексирование. В моем случае разрешено индексирование файла admin-ajax.php из запрещенной выше папки wp-admin.
В общем, поисковикам этот файл, конечно, без надобности, даже и не представляю, из каких соображений WordPress прописал это правило. Ну да мне и не жалко, в принципе
К слову, я специально добавлял выше фразу «в моем случае «, поскольку в вашем случае содержимое robots.txt уже может отличаться. Например, может быть запрещена к индексированию папка wp-includes.
Кроме директив Disallow и Allow в robots.txt мы видим директиву User-agent, для которой в качестве значения указана звездочка. Звездочка означает, что идущий далее набор правил относится ко всем поисковикам. Также можно вместо звездочки указывать названия конкретных поисковиков. Файл robots.txt поддерживает и другие директивы. Я на них останавливаться не буду, все их с примерами можно посмотреть в консоли для веб-мастеров Гугла или Яндекса. Также можете прочесть информацию на данном сайте .
Как создать robots txt для WordPress
Итак, файл для поисковых роботов у нас есть, но вполне вероятно, что он вас не устроит в текущем виде. Как же составить свой файл. Здесь есть несколько вариантов. Начнем с первого — ручное создание файла. Создайте обычный текстовый документ в блокноте и сохраните его под именем robots с расширением txt. В этом файле запишите необходимый набор правил и просто сохраните его в корень вашего сайта WordPress, рядом с файлом конфигурации wp-config.php.
На всякий случай проверьте, что файл загрузился и доступен, обратившись к нему из браузера. Это был первый способ. Второй способ — это все та же динамическая генерация файла, только теперь это сделает плагин. Если вы используете популярный плагин All in One SEO, тогда можно воспользоваться одним из его модулей.
В этой статье пример оптимального, на мой взгляд, кода для файла robots.txt под WordPress, который вы можете использовать в своих сайтах.
Для начала, вспомним зачем нужен robots.txt - файл robots.txt нужен исключительно для поисковых роботов, чтобы «сказать» им какие разделы/страницы сайта посещать, а какие посещать не нужно. Страницы, которые закрыты от посещения не будут попадать в индекс поисковиков (Yandex, Google и т.д.).
Вариант 1: оптимальный код robots.txt для WordPress
User-agent: * Disallow: /cgi-bin # классика... Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search # поиск Disallow: /author/ # архив автора Disallow: */embed # все встраивания Disallow: */page/ # все виды пагинации Allow: */uploads # открываем uploads Allow: /*/*.js # внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php #Disallow: /wp/ # когда WP установлен в подкаталог wp Sitemap: http://example.com/sitemap.xml Sitemap: http://example.com/sitemap2.xml # еще один файл #Sitemap: http://example.com/sitemap.xml.gz # сжатая версия (.gz) # Версия кода: 1.1 # Не забудьте поменять `site.ru` на ваш сайт.Разбор кода:
- Disallow: /cgi-bin - закрывает каталог скриптов на сервере
- Disallow: /feed - закрывает RSS фид блога
- Disallow: /trackback - закрывает уведомления
- Disallow: ?s= или Disallow: *?s= - закрыавет страницы поиска
- Disallow: */page/ - закрывает все виды пагинации
Правило Sitemap: http://example.com/sitemap.xml указывает роботу на файл с картой сайта в формате XML. Если у вас на сайте есть такой файл, то пропишите полный путь к нему. Таких файлов может быть несколько, тогда указываем путь к каждому отдельно.
В строке Host: site.ru мы указываем главное зеркало сайта. Если у сайта существуют зеркала (копии сайта на других доменах), то чтобы Яндекс индексировал всех их одинаково, нужно указывать главное зеркало. Директива Host: понимает только Яндекс, Google не понимает! Если сайт работает под https протоколом, то его обязательно нужно указать в Host: Host: http://example.com
Из документации Яндекса: «Host - независимая директива и работает в любом месте файла (межсекционная)». Поэтому её ставим наверх или в самый конец файла, через пустую строку.
В строке User-agent: * мы указываем, что все нижеприведенные правила будут работать для всех поисковых роботов * . Если нужно, чтобы эти правила работали только для одного, конкретного робота, то вместо * указываем имя робота (User-agent: Yandex , User-agent: Googlebot).
В строке Allow: */uploads мы намеренно разрешаем индексировать страницы, в которых встречается /uploads . Это правило обязательно, т.к. выше мы запрещаем индексировать страницы начинающихся с /wp- , а /wp- входит в /wp-content/uploads . Поэтому, чтобы перебить правило Disallow: /wp- нужна строчка Allow: */uploads , ведь по ссылкам типа /wp-content/uploads/... у нас могут лежать картинки, которые должны индексироваться, так же там могут лежать какие-то загруженные файлы, которые незачем скрывать. Allow: может быть "до" или "после" Disallow: .
Остальные строчки запрещают роботам "ходить" по ссылкам, которые начинаются с:
Потому что наличие открытых фидов требуется например для Яндекс Дзен, когда нужно подключить сайт к каналу (спасибо комментатору «Цифровой»). Возможно открытые фиды нужны где-то еще.
В тоже время, фиды имеют свой формат в заголовках ответа, благодаря которому поисковики понимают что это не HTML страница, а фид и, очевидно, обрабатывают его как-то иначе.
Директива Host для Яндекса больше не нужна
Яндекс полностью отказывается от директивы Host, её заменил 301 редирект. Host можно смело удалять из robots.txt . Однако важно, чтобы на всех зеркалах сайта стоял 301 редирект на главный сайт (главное зеркало).
Это важно: сортировка правил перед обработкой
Yandex и Google обрабатывает директивы Allow и Disallow не по порядку в котором они указаны, а сначала сортирует их от короткого правила к длинному, а затем обрабатывает последнее подходящее правило:
User-agent: * Allow: */uploads Disallow: /wp-
будет прочитана как:
User-agent: * Disallow: /wp- Allow: */uploads
Чтобы быстро понять и применять особенность сортировки, запомните такое правило: «чем длиннее правило в robots.txt, тем больший приоритет оно имеет. Если длина правил одинаковая, то приоритет отдается директиве Allow.»
Вариант 2: стандартный robots.txt для WordPress
Не знаю кто как, а я за первый вариант! Потому что он логичнее - не надо полностью дублировать секцию ради того, чтобы указать директиву Host для Яндекса, которая является межсекционной (понимается роботом в любом месте шаблона, без указания к какому роботу она относится). Что касается нестандартной директивы Allow , то она работает для Яндекса и Гугла и если она не откроет папку uploads для других роботов, которые её не понимают, то в 99% ничего опасного это за собой не повлечет. Я пока не заметил что первый robots работает не так как нужно.
Вышеприведенный код немного не корректный. Спасибо комментатору " " за указание на некорректность, правда в чем она заключалась пришлось разбираться самому. И вот к чему я пришел (могу ошибаться):
- Директиву Яндекса Host: нужно использовать после Disallow: , потому что некоторые роботы (не Яндекса и Гугла), могут не понять её и вообще забраковать robots.txt. Cамому же Яндексу, судя по документации , абсолютно все равно где и как использовать Host: , хоть вообще создавай robots.txt с одной только строчкой Host: www.site.ru , для того, чтобы склеить все зеркала сайта.
Некоторые роботы (не Яндекса и Гугла) - не понимают более 2 директив: User-agent: и Disallow:
3. Sitemap: межсекционная директива для Яндекса и Google и видимо для многих других роботов тоже, поэтому её пишем в конце через пустую строку и она будет работать для всех роботов сразу.
На основе этих поправок, корректный код должен выглядеть так:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-json/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */embed Disallow: */page/ Disallow: /cgi-bin Disallow: *?s= Allow: /wp-admin/admin-ajax.php Host: site.ru User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-json/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */embed Disallow: */page/ Disallow: /cgi-bin Disallow: *?s= Allow: /wp-admin/admin-ajax.php Sitemap: http://example.com/sitemap.xmlДописываем под себя
Если вам нужно запретить еще какие-либо страницы или группы страниц, можете внизу добавить правило (директиву) Disallow: . Например, нам нужно закрыть от индексации все записи в категории news , тогда перед Sitemap: добавляем правило:
Disallow: /news
Оно запретить роботам ходить по подобным ссылками:
- http://example.com/news
- http://example.com/news/drugoe-nazvanie/
Если нужно закрыть любые вхождения /news , то пишем:
Disallow: */news
- http://example.com/news
- http://example.com/my/news/drugoe-nazvanie/
- http://example.com/category/newsletter-nazvanie.html
Подробнее изучить директивы robots.txt вы можете на странице помощи Яндекса (но имейте ввиду, что не все правила, которые описаны там, работают для Google).
Проверка robots.txt и документация
Проверить правильно ли работают прописанные правила можно по следующим ссылкам:
- Яндекс: http://webmaster.yandex.ru/robots.xml .
- В Google это делается в Search console . Нужна авторизация и наличия сайта в панели веб-мастера...
- Сервис для создания файла robots.txt: http://pr-cy.ru/robots/
- Сервис для создания и проверки robots.txt: https://seolib.ru/tools/generate/robots/
Я спросил у Яндекса...
Задал вопрос в тех. поддержку Яндекса насчет межсекционного использования директив Host и Sitemap:
Вопрос:
Здравствуйте!
Пишу статью насчет robots.txt на своем блоге. Хотелось бы получить ответ на такой вопрос (в документации я не нашел однозначного "да"):Если мне нужно склеить все зеркала и для этого я использую директиву Host в самом начале фала robots.txt:
Host: site.ru User-agent: * Disallow: /asd
Будет ли в данном примере правильно работать Host: site.ru? Будет ли она указывать роботам что site.ru это основное зеркало. Т.е. эту директиву я использую не в секции, а отдельно (в начале файла) без указания к какому User-agent она относится.
Также хотел узнать, обязательно ли директиву Sitemap нужно использовать внутри секции или можно использовать за пределами: например, через пустую строчку, после секции?
User-agent: Yandex Disallow: /asd User-agent: * Disallow: /asd Sitemap: http://example.com/sitemap.xml
Поймет ли робот в данном примере директиву Sitemap?
Надеюсь получить от вас ответ, который поставит жирную точку в моих сомнениях.
Ответ:
Здравствуйте!
Директивы Host и Sitemap являются межсекционными, поэтому будут использоваться роботом вне зависимости от места в файле robots.txt, где они указаны.
--
С уважением, Платон Щукин
Служба поддержки Яндекса
Заключение
Важно помнить, что изменения в robots.txt на уже рабочем сайте будут заметны только спустя несколько месяцев (2-3 месяца).
Ходят слухи, что Google иногда может проигнорировать правила в robots.txt и взять страницу в индекс, если сочтет, что страница ну очень уникальная и полезная и она просто обязана быть в индексе. Однако другие слухи опровергают эту гипотезу тем, что неопытные оптимизаторы могут неправильно указать правила в robots.txt и так закрыть нужные страницы от индексации и оставить ненужные. Я больше склоняюсь ко второму предположению...
Динамический robots.txt
В WordPress запрос на файл robots.txt обрабатывается отдельно и совсем не обязательно физически создавать файл robots.txt в корне сайта, более того это не рекомендуется, потому что при таком подходе плагинам будет очень сложно изменить этот файл, а это иногда нужно.
О том как работает динамическое создание файла robots.txt читайте в описании функции , а ниже я приведу пример как можно изменить содержание этого файла, налету, через хук .
Для этого добавьте следующий код в файл functions.php:
Add_action("do_robotstxt", "my_robotstxt"); function my_robotstxt(){ $lines = [ "User-agent: *", "Disallow: /wp-admin/", "Disallow: /wp-includes/", "", ]; echo implode("\r\n", $lines); die; // обрываем работу PHP }
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/
Crawl-delay - таймаут для сумасшедших роботов (с 2018 года не учитывается)
Яндекс
Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay в robots.txt […] Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Когда робот Яндекса сканирует сайт как сумасшедший и это создает излишнюю нагрузку на сервер. Робота можно попросить «поубавить обороты».
Для этого нужно использовать директиву Crawl-delay . Она указывает время в секундах, которое робот должен простаивать (ждать) для сканирования каждой следующей страницы сайта.
Для совместимости с роботами, которые плохо следуют стандарту robots.txt, Crawl-delay нужно указывать в группе (в секции User-Agent) сразу после Disallow и Allow
Робот Яндекса понимает дробные значения, например, 0.5 (пол секунды). Это не гарантирует, что поисковый робот будет заходить на ваш сайт каждые полсекунды, но позволяет ускорить обход сайта.
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Crawl-delay: 1.5 # таймаут в 1.5 секунды User-agent: * Disallow: /wp-admin Disallow: /wp-includes Allow: /wp-*.gif Crawl-delay: 2 # таймаут в 2 секунды
Робот Google не понимает директиву Crawl-delay . Таймаут его роботам можно указать в панели вебмастера.
На сервисе avi1.ru Вы можете уже сейчас приобрести продвижение SMM более чем в 7 самых популярных социальных сетях. При этом обратите внимание на достаточно низкую стоимость всех услуг сайта.