Как осуществляется поиск в поисковых системах. Как работают поисковые системы — сниппеты, алгоритм обратного поиска, индексация страниц и особенности работы Яндекса
Здравствуйте, уважаемые читатели!
Поисковых систем в мировом интернет-пространстве в настоящий момент достаточно много. У каждой из них имеются собственные алгоритмы индексирования и ранжирования сайтов, но в целом принцип работы поисковиков довольно похож.
Знания о том, как работает поисковая система в условиях стремительно растущей конкуренции являются весомым преимуществом при продвижении не только коммерческих, но и информационных сайтов и блогов. Эти знания помогают выстраивать эффективную стратегию оптимизации сайта и с меньшими усилиями попадать в ТОП выдачи по продвигаемым группам запросов.
Принципы работы поисковых систем
Смысл работы оптимизатора состоит в том, чтобы «подстроить» продвигаемые страницы под поисковые алгоритмы и, тем самым, помочь этим страницам достичь высоких позиций по определенным запросам. Но до начала работ по оптимизации сайта или блога необходимо хотя бы поверхностно разбираться в особенностях работы поисковых систем, чтобы понимать, как они могут реагировать на предпринимаемые оптимизатором действия.
Разумеется, детальные подробности формирования поисковой выдачи – информация, которую поисковые системы не разглашают. Однако, для правильных усилий по достаточно понимания главных принципов, по которым работают поисковые системы.
Методы поиска информации
Два основных метода, используемых сегодня поисковыми машинами, отличаются подходом к поиску информации.
- Алгоритм прямого поиска , предполагающий сопоставление каждому из документов, сохраненных в базе поисковой системы, ключевой фразы (запроса пользователя), является достаточно надежным методом, который позволяет найти всю необходимую информацию. Недостаток этого метода заключается в том, что при поиске в больших массивах данных время, требуемое для нахождения ответа, достаточно велико.
- Алгоритм обратных индексов , когда ключевой фразе сопоставляется список документов, в которых она присутствует, удобен при взаимодействии с базами данных, содержащими десятки и сотни миллионов страниц. При таком подходе поиск производится не по всем документам, а только по специальным файлам, включающим списки слов, содержащихся на страницах сайтов. Каждое слово в подобном списке сопровождается указанием координат позиций, где оно встречается, и прочих параметров. Именно этот метод применяется сегодня в работе таких известных поисковых систем, как Яндекс и Гугл.
Здесь следует отметить, что при обращении пользователя к поисковой строке браузера поиск производится не непосредственно в интернете, а в предварительно собранных, сохраненных и актуальных на данный момент базах данных, содержащих обработанные поисковиками блоки информации (страницы сайтов). Быстрое формирование результатов поиска возможно именно благодаря работе с обратными индексами.

Текстовое содержимое страниц (прямые индексы) поисковыми машинами тоже сохраняется и используется при автоматическом формировании сниппетов из наиболее подходящих запросу текстовых фрагментов.
Математическая модель ранжирования
С целью ускорения поиска и упрощения процесса формирования выдачи, максимально отвечающей запросу пользователя, применяется определенная математическая модель. Задача этой математической модели — нахождение нужных страниц в актуальной базе обратных индексов, оценка их степени соответствия запросу и распределение в порядке убывания релевантности.
Простого нахождения нужной фразы на странице недостаточно. При определении поисковиками применяется расчет веса документа относительно пользовательского запроса. По каждому запросу этот параметр рассчитывается на основе следующих данных: частоты использования на анализируемой странице и коэффициентом, отражающим насколько редко встречается это же слово в других документах базы данных поисковика. Произведение этих двух величин и соответствует весу документа.
Разумеется, представленный алгоритм является весьма упрощенным, поскольку в распоряжении поисковых машин есть ряд других дополнительных коэффициентов, используемых при расчетах, но смысл от этого не меняется. Чем чаще отдельное слово из запроса пользователя встречается в каком-либо документе, тем выше вес последнего. При этом текстовое содержимое страницы признается спамным, если будут превышены определенные пределы, являющиеся для каждого запроса различными.
Основные функции поисковой системы
Все существующие системы поиска призваны выполнять несколько важных функций: поиск информации, ее индексирование, качественную оценку, правильное ранжирование и формирование поисковой выдачи. Первоочередная задача любого поисковика – предоставление пользователю той информации, которую он ищет, максимально точного ответа на конкретный запрос.
Поскольку большинство пользователей понятия не имеют о том, как работают поисковые системы в интернете и возможности обучить пользователей «правильному» поиску весьма ограничены (например, поисковыми подсказками), разработчики вынуждены улучшать сам поиск. Последнее подразумевает создание алгоритмов и принципов работы поисковых систем, позволяющих находить требуемую информацию независимо от того, насколько «правильно» сформулирован поисковый запрос.
Сканирование
Это отслеживание изменений в уже проиндексированных документах и поиск новых страниц, которые могут быть представлены в результатах выдачи на запросы пользователей. Сканирование ресурсов в сети интернет поисковики осуществляют с помощью специализированных программ, называемых пауками или поисковыми роботами.
Сканирование интернет-ресурсов и сбор данных производится поисковыми ботами автоматически. После первого посещения сайта и включения его в базу данных поиска, роботы начинают периодически посещать этот сайт, чтобы отслеживать и фиксировать произошедшие в контенте изменения.
Поскольку количество развивающихся ресурсов в интернете велико, а новые сайты появляются ежедневно, описанный процесс не останавливается ни на минуту. Такой принцип работы поисковых систем в интернете позволяет им всегда располагать актуальной информацией о доступных в сети сайтах и их контенте.
Основная задача поискового робота – поиск новых данных и передача их поисковику для дальнейшей обработки.

Индексирование
Поисковая система способна находить данные только на сайтах, представленных в ее базе – иначе говоря, проиндексированных. На этом шаге поисковик должен определить, следует ли найденную информацию заносить в базу данных и, если заносить, то в какой из разделов. Этот процесс также выполняется в автоматическом режиме.
Считается, что Google индексирует почти всю доступную в сети информацию, Яндекс же к индексации контента подходит более избирательно и не так быстро. Оба поисковых гиганта рунета работают на благо пользователя, но общие принципы работы поисковой системы Гугл и Яндекс несколько отличаются, так как основаны на уникальных, составляющих каждую систему программных решениях.
Общим же для поисковых систем моментом является то, что процесс индексирования всех новых ресурсов занимает более продолжительное время, чем индексирование нового контента на известных системе сайтах. Информация, появляющаяся на сайтах, доверие поисковиков к которым высоко, попадает в индекс практически моментально.
Ранжирование
Ранжирование – это оценка алгоритмами поисковика значимости проиндексированных данных и выстраивание их в соответствии c факторами, свойственными данному поисковику. Полученная информация обрабатывается с целью формирования результатов поиска по всему спектру пользовательских запросов. То, какая именно информация будет представлена в результатах поиска выше, а какая ниже, полностью определяется тем, как работает выбранная поисковая система и ее алгоритмы.
Сайты, находящиеся в базе поисковой системы, распределяются по тематикам и группам запросов. Для каждой группы запросов формируется предварительная выдача, подвергающаяся в дальнейшем корректировке. Позиции большинства сайтов изменяются после каждого апдейта выдачи — обновления ранжирования, которое в Google происходит ежедневно, в поиске Яндекса – раз в несколько дней.
Человек как помощник в борьбе за качество выдачи
Реальность такова, что даже самые продвинутые системы поиска, такие как Яндекс и Гугл, на данный момент все еще нуждаются в помощи человека для формирования выдачи, соответствующей принятым стандартам качества. Там, где поисковый алгоритм срабатывает недостаточно хорошо, результаты его корректируются вручную – путем оценки содержимого страницы по множеству критериев.
Многочисленной армии специально обученных людей из разных стран – модераторов (асессоров) поисковых систем – приходится ежедневно выполнять огромный объем работы по проверке соответствия страниц сайтов пользовательским запросам, фильтрации выдачи от спама и запрещенного контента (текстов, изображений, видео). Работа асессоров позволяет делать выдачу чище и способствует дальнейшему развитию самообучающихся поисковых алгоритмов.

Заключение
С развитием сети интернет и постепенным изменением стандартов и форм представления контента меняется и подход к поиску, совершенствуются процессы индексирования и ранжирования информации, используемые алгоритмы, появляются новые факторы ранжирования. Все это позволяет поисковым системам формировать наиболее качественную и адекватную запросам пользователя выдачу, но при этом усложняет жизнь вебмастерам и специалистам, занимающимся продвижением сайтов.
В комментариях под статьей предлагаю высказаться о том, какая из основных поисковых систем рунета – Яндекс или Гугл, по вашему мнению, работает лучше, предоставляя пользователю более качественный поиск, и почему.
Интернет необходим многим пользователям для того, чтобы получать ответы на запросы (вопросы), которые они вводят.
Если бы не было поисковых систем, пользователям пришлось бы самостоятельно искать нужные сайты, запоминать их, записывать. Во многих случаях найти «вручную» что-то подходящее было бы весьма сложно, а часто и просто невозможно.
За нас всю эту рутинную работу по поиску, хранению и сортировке информации на сайтах .
Начнем с известных поисковиков Рунета.
Поисковые системы в Интернете на русском
1) Начнем с отечественной поисковой системы. Яндекс работает не только в России, но также работает в Белоруссии и Казахстане, в Украине, в Турции. Также есть Яндекс на английском языке.
2) Поисковик Google пришел к нам из Америки, имеет русскоязычную локализацию:
3)Отечественный поисковик Майл ру, который одновременно представляет социальную сеть ВКонтакте, Одноклассники, также Мой мир, известные Ответы Mail.ru и другие проекты.
4) Интеллектуальная поисковая система
Nigma (Нигма) http://www.nigma.ru/
С 19 сентября 2017 года “интеллектуалка” nigma не работает. Она перестала для её создателей представлять финансовый интерес, они переключились на другой поисковик под названием CocCoc.
5) Известная компания Ростелеком создала поисковую систему Спутник.
Есть поисковик Спутник, разработанный специально для детей, про который я писала .
6) Рамблер был одним из первых отечественных поисковиков:
В мире есть другие известные поисковики:
- Bing,
- Yahoo!,
- Baidu,
- Ecosia,
Попробуем разобраться, как же работает поисковая система, а именно, как происходит индексация сайтов, анализ результатов индексации и формирование поисковой выдачи. Принципы работы поисковых систем примерно одинаковые: поиск информации в Интернете, ее хранение и сортировка для выдачи в ответ на запросы пользователей. А вот алгоритмы, по которым работают поисковики, могут сильно отличаться. Эти алгоритмы держатся в тайне и запрещено ее разглашение.
Введя один и тот же запрос в поисковые строки разных поисковиков, можно получить разные ответы. Причина в том, что все поисковики используют собственные алгоритмы.
Цель поисковиков
В первую очередь нужно знать о том, что поисковики – это коммерческие организации. Их цель – получение прибыли. Прибыль можно получать с контекстной рекламы, других видов рекламы, с продвижения нужных сайтов на верхние строчки выдачи. В общем, способов много.
Зависит от того, какой размер аудитории у него, то есть, сколько человек пользуется данной поисковой системой. Чем больше аудитория, тем большему числу людей будет показываться реклама. Соответственно, стоить эта реклама будет больше. Увеличить аудиторию поисковики могут за счет собственной рекламы, а также привлекая пользователей за счет улучшения качества своих сервисов, алгоритма и удобства поиска.
Самое главное и сложное здесь – это разработка полноценного функционирующего алгоритма поиска, который бы предоставлял релевантные результаты на большинство пользовательских запросов.
Работа поисковика и действия вебмастеров
Каждый поисковик обладает своим собственным алгоритмом, который должен учитывать огромное количество разных факторов при анализе информации и составлении выдачи в ответ на запрос пользователя:
- возраст того или иного сайта,
- характеристики домена сайта,
- качество контента на сайте и его виды,
- особенности навигации и структуры сайта,
- юзабилити (удобство для пользователей),
- поведенческие факторы (поисковик может определить, нашел ли пользователь то, что он искал на сайте или пользователь вернулся снова в поисковик и там опять ищет ответ на тот же запрос)
- и т.д.
Все это нужно именно для того, чтобы выдача по запросу пользователя была максимально релевантной, удовлетворяющей запросы пользователя. При этом алгоритмы поисковиков постоянно меняются, дорабатываются. Как говорится, нет предела совершенству.
С другой стороны, вебмастера и оптимизаторы постоянно изобретают новые способы продвижения своих сайтов, которые далеко не всегда являются честными. Задача разработчиков алгоритма поисковых машин – вносить в него изменения, которые бы не позволяли «плохим» сайтам нечестных оптимизаторов оказываться в ТОПе.
Как работает поисковая система?
Теперь о том, как происходит непосредственная работа поисковой системы. Она состоит как минимум из трех этапов:
- сканирование,
- индексирование,
- ранжирование.
Число сайтов в интернете достигает просто астрономической величины. И каждый сайт – это информация, информационный контент, который создается для читателей (живых людей).
Сканирование
Это блуждание поисковика по Интернету для сбора новой информации, для анализа ссылок и поиска нового контента, который можно использовать для выдачи пользователю в ответ на его запросы. Для сканирования у поисковиков есть специальные роботы, которых называют поисковыми роботами или пауками.
Поисковые роботы – это программы, которые в автоматическом режиме посещают сайты и собирают с них информацию. Сканирование может быть первичным (робот заходит на новый сайт в первый раз). После первичного сбора информации с сайта и занесения его в базу данных поисковика, робот начинает с определенной регулярностью заходить на его страницы. Если произошли какие-то изменения (добавился новый контент, удалился старый), то все эти изменения будут поисковиком зафиксированы.
Главная задача поискового паука – найти новую информацию и отдать ее поисковику на следующий этап обработки, то есть, на индексирование.
Индексирование
Поисковик может искать информацию лишь среди тех сайтов, которые уже занесены в его базу данных (проиндексированы им). Если сканирование – это процесс поиска и сбора информации, которая имеется на том или ином сайте, то индексация – процесс занесения этой информации в базу данных поисковика. На этом этапе поисковик автоматически принимает решение, стоит ли заносить ту или иную информацию в свою базу данных и куда ее заносить, в какой раздел базы данных. Например, Google индексирует практически всю информацию, найденную его роботами в Интернете, а Яндекс более привередлив и индексирует далеко не все.
Для новых сайтов этап индексирования может быть долгим, поэтому посетителей из поисковых систем новые сайты могут ждать долго. А новая информация, которая появляется на старых, раскрученных сайтах, может индексироваться почти мгновенно и практически сразу попадать в «индекс», то есть, в базу данных поисковиков.
Ранжирование
Ранжирование – это выстраивание информации, которая была ранее проиндексирована и занесена в базу того или иного поисковика, по рангу, то есть, какую информацию поисковик будет показывать своим пользователям в первую очередь, а какую информацию помещать «рангом» ниже. Ранжирование можно отнести к этапу обслуживания поисковиком своего клиента – пользователя.
На серверах поисковой системы происходит обработка полученной информации и формирование выдачи по огромному спектру всевозможных запросов. Здесь уже вступают в работу алгоритмы поисковика. Все занесенные в базу сайты классифицируются по тематикам, тематики делятся на группы запросов. По каждой из групп запросов может составляться предварительная выдача, которая впоследствии будет корректироваться.
Зачем маркетологу знать базовые принципы поисковой оптимизации? Все просто: органический трафик — это прекрасный источник входящего потока целевой аудитории для вашего корпоративного сайта и даже лендингов.
Встречайте серию образовательных постов на тему SEO.
Что такое поисковая система?
Поисковая система представляет собой большую базу документов (контента). Поисковые роботы обходят ресурсы и индексируют разный тип контента, именно эти сохраненные документы и ранжируют в поиске.
По факту, Яндекс — это «слепок» Рунета (еще Турция и немного англоязычных сайтов), а Google — мирового интернета.
Поисковый индекс — структура данных, содержащая информацию о документах и расположении в них ключевых слов.
По принципу работы поисковые системы схожи между собой, различия заключаются в формулах ранжирования (упорядочивание сайтов в поисковой выдаче), которые строятся на основе машинного обучения.
Ежедневно миллионы пользователей задают запросы поисковым системам.
«Реферат написать»:

«Купить»:
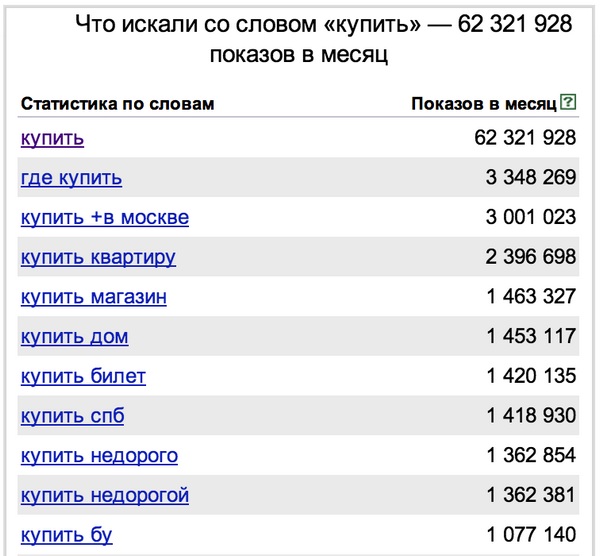
Но больше всего интересуются…

Как устроена поисковая система?
Чтобы предоставлять пользователям быстрые ответы, архитектуру поиска разделили на 2 части:
- базовый поиск,
- метапоиск.

Базовый поиск
Базовый поиск — программа, которая производит поиск по своей части индекса и предоставляет все соответствующие запросу документы.
Метапоиск — программа, которая обрабатывает поисковый запрос, определяет региональность пользователя, и если запрос популярный, то выдает уже готовый вариант выдачи, а если запрос новый, то выбирает базовый поиск и отдает команду на подбор документов, далее методом машинного обучения ранжирует найденные документы и предоставляет пользователю.

Классификация поисковых запросов
Чтобы дать релевантный ответ пользователю, поисковик сначала пытается понять, что ему конкретно нужно. Происходит анализ поискового запроса и параллельный анализ пользователя.
Поисковые запросы анализируются по параметрам:
- Длина;
- четкость;
- популярность;
- конкурентность;
- синтаксис;
- география.
Тип запроса:
- навигационный;
- информационный;
- транзакционный;
- мультимедийный;
- общий;
- служебный.
После разбора и классификации запроса происходит подбор функции ранжирования.

Обозначение типов запросов является конфиденциальной информацией и предложенные варианты — это догадка специалистов по поисковому продвижению.
Если пользователь задает общий запрос, то поисковая система выдает разные типы документов. И стоит понимать, что продвигая коммерческую страницу сайта в ТОП-10 по общему запросу, вы претендуете попасть не на одно из 10 мест, а в число мест
для коммерческих страниц, которое выделяется формулой ранжирования. И следовательно, вероятность вывода в топ по таким запросам ниже.
Машинное обучение МатриксНет — алгоритм, введенный в 2009 году Яндексом, подбирающий функцию ранжирования документов по определенным запросам.

МатриксНет используется не только в поиске Яндекса, но и в научных целях. К примеру, в Европейском Центре ядерных исследований его используют для редких событий в больших объемах данных (ищут бозон Хиггса).
Первичные данные для оценки эффективности формулы ранжирования собирает отдел асессоров. Это специально обученные люди, которые оценивают выборку сайтов по экспериментальной формуле по следующим критериям.
Оценка качества сайта
Витальный — официальный сайт (Сбербанк, LPgenerator). Поисковому запросу соответствует официальный сайт, группы в социальных сетях, информация на авторитетных ресурсах.
Полезный (оценка 5) — сайт, который предоставляет расширенную информацию по запросу.
Пример — запрос: баннерная ткань.
Сайт, соответствующий оценке «полезный», должен содержать информацию:
- что такое баннерная ткань;
- технические характеристики;
- фотографии;
- виды;
- прайс-лист;
- что-то еще.
Примеры запроса в топе:

Релевантный+ (оценка 4) — это оценка означает, что страница соответствует поисковому запросу.
Релевантный- (оценка 3) — страница не точно соответствует поисковому запросу.
Допустим, по запросу «стражи галактики сеансы» выводится страница о фильме без сеансов, страница прошедшего сеанса, страница трейлера на youtube.
Нерелевантный (оценка 2) — страница не соответствует запросу.
Пример: по названию отеля выводится название другого отеля.
Чтобы продвинуть ресурс по общему или информационному запросу, нужно создавать страницу соответствующую оценке «полезный».
Для четких запросов достаточно соответствовать оценке «релевантный+».
Релевантность достигается за счет текстового и ссылочного соответствия страницы поисковым запросам.
Выводы
- Не по всем запросам можно продвинуть коммерческую целевую страницу;
- Не по всем информационным запросам можно продвинуть коммерческий сайт;
- Продвигая общий запрос, создавайте полезную страницу.
Частой причиной, почему сайт не выходит в топ, является несоответствие контента продвигаемой страницы, поисковому запросу.
Об этом поговорим в следующей статье «Чек-лист по базовой оптимизации сайта».
По определению, интернет-поисковик это система поиска информации, которая помогает нам найти информацию во всемирной паутине. Это облегчает глобальный обмен информацией. Но интернет является неструктурированной базой данных. Он растет в геометрической прогрессии, и стал огромным хранилищем информации. Поиск информации в интернете, является трудной задачей. Существует необходимость иметь инструмент для управления, фильтра и извлечения этой океанической информации. Поисковая система служит для этой цели.
Как работает поисковая система?
Поисковые системы интернета являются двигателями, поиска и извлечения информации в интернете. Большинство из них используют гусеничную архитектуру индексатора. Они зависят от их гусеничных модулей. Сканеры также называют пауками это небольшие программы, которые просматривают веб-страницы.
Сканеры посещают первоначальный набор URL-адресов. Они добывают URL-адреса, которые появляются на просканированных страницах и отправляют эту информацию в модуль гусеничный управления. Гусеничный модуль решает, какие страницы посетить в следующий раз и дает эти URL-адреса сканерам.
Темы, охватываемые различными поисковыми системами, варьируются в зависимости от алгоритмов, которые они используют. Некоторые поисковые системы запрограммированы на поисковые сайты по конкретной теме, в то время как сканеры других могут посещать столько мест, сколько возможно.
Модуль индексации извлекает информацию из каждой страницы, которую он посещает и вносит URL в базу. Это приводит к образованию огромной таблицы поиска, из списка URL-адресов указывающих на страницы с информацией. В таблице приведены те страницы, которые были покрыты в процессе обхода.
Модуль анализа является еще одной важной частью архитектуры поисковой системы. Он создает индекс полезности. Индекс утилита может предоставить доступ к страницам заданной длины или страниц, содержащих определенное количество картинок на них.
В процессе сканирования и индексирования, поисковик сохраняет страницы, которые он извлекает. Они временно хранятся в хранилище страницы. Поисковые системы поддерживают кэш страниц которые они посещают, чтобы ускорить извлечение уже посещенных страниц.
Модуль запроса поисковой системы получает поисковый запросов от пользователей в виде ключевых слов. Модуль ранжирования сортирует результаты.
Архитектура гусеничного индексатора имеет много вариантов. Они изменяются в распределенной архитектуре поисковой системы. Эти архитектуры состоят из собирателей и брокеров. Собиратели собирают информацию индексации с веб-серверов в то время как брокеры дают механизм индексирования и интерфейс запросов. Брокеры индексируют обновление на основе информации, полученной от собирателей и других брокеров. Они могут фильтровать информацию. Многие поисковые системы сегодня используют этот тип архитектуры.
Поисковые системы и ранжирования страниц
Когда мы создаем запрос в поисковой системе, результаты отображаются в определенном порядке. Большинство из нас, как правило, посещают страницы верхнего порядка и игнорируют последние. Это потому, что мы считаем, что верхние несколько страниц несут большую актуальность для нашего запроса. Так что все заинтересованы в рейтинге своих страниц в первых десяти результатов в поисковой системе.
Слова, указанные в интерфейсе запроса поисковой системы являются ключевыми словами, которые запрашивались в поисковых системах. Они представляют собой список страниц, имеющих отношение к запрашиваемым ключевым словам. Во время этого процесса, поисковые системы извлекают те страницы, которые имеют частые вхождений этих ключевых слов. Они ищут взаимосвязи между ключевыми словами. Расположение ключевых слов также считается, как и рейтинг страницы, содержащие их. Ключевые слова, которые встречаются в заголовках страниц или в URL, приведены в больший вес. Страницы, имеющие ссылки, указывающие на них, делают их еще более популярными. Если многие другие сайты, ссылаются на какую либо страницу, она рассматривается как ценная и более актуальная.
Существует алгоритм ранжирования, который использует каждая поисковая система. Алгоритм представляет собой компьютеризированную формулу разработанную, чтобы предоставлять соответствующие страницы по запросу пользователя. Каждая поисковая система может иметь различный алгоритм ранжирования, который анализирует страницы в базе данных двигателя, чтобы определить соответствующие ответы на поисковые запросы. Различные сведения поисковые системы индексируют по-разному. Это приводит к тому, что конкретный запрос, поставленный двум различным поисковым машинам, может принести страницы в различных порядках или извлечь разные страницы. Популярность веб-сайта являются факторами, определяющими актуальность. Клик-через популярность сайта является еще одним фактором, определяющим его ранг. Это мера того, насколько часто посещают сайт.
Веб-мастера пытаются обмануть алгоритмы поисковой системы, чтобы поднять позиции своего сайта в поисковой выдаче. Заполняют страницы сайта ключевыми словами или используют мета теги, чтобы обмануть стратегии рейтинга поисковой системы. Но поисковые системы достаточно умны! Они совершенствуют свои алгоритмы так, чтобы махинации веб-мастеров не влияли на поисковую выдачу.
Нужно понимать, что даже страницы после первых нескольких в списке могут содержать именно ту информацию, которую вы искали. Но будьте уверены, что хорошие поисковые системы всегда принесут вам высоко релевантные страницы в верхнем порядке!
Что это
DuckDuckGo - это довольно известная поисковая система с открытым исходным кодом. Серверы находятся в США. Кроме собственного робота, поисковик использует результаты других источников: Yahoo, Bing, «Википедии».
Чем лучше
DuckDuckGo позиционирует себя как поиск, обеспечивающий максимальную приватность и конфиденциальность. Система не собирает никаких данных о пользователе, не хранит логи (нет истории поиска), использование файлов cookie максимально ограничено.
DuckDuckGo не собирает личную информацию пользователей и не делится ею. Это наша политика конфиденциальности.
Гэбриел Вайнберг (Gabriel Weinberg), основатель DuckDuckGo
Зачем это вам
Все крупные поисковые системы стараются персонализировать поисковую выдачу на основе данных о человеке перед монитором. Этот феномен получил название «пузырь фильтров»: пользователь видит только те результаты, которые согласуются с его предпочтениями или которые система сочтёт таковыми.
Формирует объективную картину, не зависящую от вашего прошлого поведения в Сети, и избавляет от тематической рекламы Google и «Яндекса», основанной на ваших запросах. При помощи DuckDuckGo легко искать информацию на иностранных языках, тогда как Google и «Яндекс» по умолчанию отдают предпочтение русскоязычным сайтам, даже если запрос введён на другом языке.

Что это
not Evil - система, осуществляющая поиск по анонимной сети Tor. Для использования нужно зайти в эту сеть, например запустив специализированный .
not Evil не единственный поисковик в своём роде. Есть LOOK (поиск по умолчанию в Tor-браузере, доступен из обычного интернета) или TORCH (один из самых старых поисковиков в Tor-сети) и другие. Мы остановились на not Evil из-за недвусмысленного намёка на Google (достаточно посмотреть на стартовую страницу).
Чем лучше
Ищет там, куда Google, «Яндексу» и другим поисковикам вход закрыт в принципе.
Зачем это вам
В сети Tor много ресурсов, которые невозможно встретить в законопослушном интернете. И их число будет расти по мере того, как ужесточается контроль властей над содержанием Сети. Tor - это своеобразная сеть внутри Сети со своими социалками, торрент-трекерами, СМИ, торговыми площадками, блогами, библиотеками и так далее.
3. YaCy

Что это
YaCy - децентрализованная поисковая система, работающая по принципу сетей P2P. Каждый компьютер, на котором установлен основной программный модуль, сканирует интернет самостоятельно, то есть является аналогом поискового робота. Полученные результаты собираются в общую базу, которую используют все участники YaCy.
Чем лучше
Здесь сложно говорить, лучше это или хуже, так как YaCy - это совершенно иной подход к организации поиска. Отсутствие единого сервера и компании-владельца делает результаты полностью независимыми от чьих-то предпочтений. Автономность каждого узла исключает цензуру. YaCy способен вести поиск в глубоком вебе и неиндексируемых сетях общего пользования.
Зачем это вам
Если вы сторонник открытого ПО и свободного интернета, не подверженного влиянию государственных органов и крупных корпораций, то YaCy - это ваш выбор. Также с его помощью можно организовать поиск внутри корпоративной или другой автономной сети. И пусть пока в быту YaCy не слишком полезен, он является достойной альтернативой Google с точки зрения процесса поиска.
4. Pipl

Что это
Pipl - система, предназначенная для поиска информации о конкретном человеке.
Чем лучше
Авторы Pipl утверждают, что их специализированные алгоритмы ищут эффективнее, чем «обычные» поисковики. В частности, приоритетными являются профили социальных сетей, комментарии, списки участников и различные базы данных, где публикуются сведения о людях, например базы судебных решений. Лидерство Pipl в этой области подтверждено оценками Lifehacker.com, TechCrunch и других изданий.
Зачем это вам
Если вам нужно найти информацию о человеке, проживающем в США, то Pipl будет намного эффективнее Google. Базы данных российских судов, видимо, недоступны для поисковика. Поэтому с гражданами России он справляется не так хорошо.

Что это
FindSounds - ещё один специализированный поисковик. Ищет в открытых источниках различные звуки: дом, природа, машины, люди и так далее. Сервис не поддерживает запросы на русском языке, но есть внушительный список русскоязычных тегов, по которым можно выполнять поиск.
Чем лучше
В выдаче только звуки и ничего лишнего. В настройках можно выставить желаемый формат и качество звучания. Все найденные звуки доступны для скачивания. Имеется поиск по образцу.
Зачем это вам
Если вам нужно быстро найти звук мушкетного выстрела, удары дятла-сосуна или крик Гомера Симпсона, то этот сервис для вас. И это мы выбрали только из доступных русскоязычных запросов. На английском языке спектр ещё шире.
Если серьёзно, специализированный сервис предполагает специализированную аудиторию. Но вдруг и вам пригодится?

Что это
Wolfram|Alpha - вычислительно-поисковая система. Вместо ссылок на статьи, содержащие ключевые слова, она выдаёт готовый ответ на запрос пользователя. Например, если ввести в форму поиска «сравнить население Нью-Йорка и Сан-Франциско» на английском, то Wolfram|Alpha сразу выведет на экран таблицы и графики со сравнением.
Чем лучше
Этот сервис лучше других подходит для поиска фактов и вычисления данных. Wolfram|Alpha накапливает и систематизирует доступные в Сети знания из различных областей, включая науку, культуру и развлечения. Если в этой базе находится готовый ответ на поисковый запрос, система показывает его, если нет - вычисляет и выводит результат. При этом пользователь видит только и ничего лишнего.
Зачем это вам
Если вы, например, студент, аналитик, журналист или научный сотрудник, то можете использовать Wolfram|Alpha для поиска и вычисления данных, связанных с вашей деятельностью. Сервис понимает не все запросы, но постоянно развивается и становится умнее.

Что это
Метапоисковик Dogpile выводит комбинированный список результатов из поисковых выдач Google, Yahoo и других популярных систем.
Чем лучше
Во-первых, Dogpile отображает меньше рекламы. Во-вторых, сервис использует особый алгоритм, чтобы находить и показывать лучшие результаты из разных поисковиков. Как утверждают разработчики Dogpile, их системы формирует самую полную выдачу во всём интернете.
Зачем это вам
Если вы не можете найти информацию в Google или другом стандартном поисковике, поищите её сразу в нескольких поисковиках с помощью Dogpile.

Что это
BoardReader - система для текстового поиска по форумам, сервисам вопросов и ответов и другим сообществам.
Чем лучше
Сервис позволяет сузить поле поиска до социальных площадок. Благодаря специальным фильтрам вы можете быстро находить посты и комментарии, которые соответствуют вашим критериям: языку, дате публикации и названию сайта.
Зачем это вам
BoardReader может пригодиться пиарщикам и другим специалистам в области медиа, которых интересует мнение массовой по тем или иным вопросам.
В заключение
Жизнь альтернативных поисковиков часто бывает скоротечной. О долгосрочных перспективах подобных проектов Лайфхакер спросил бывшего генерального директора украинского филиала компании «Яндекс» Сергея Петренко .

Сергей Петренко
Бывший генеральный директор «Яндекс.Украины».
Что касается судьбы альтернативных поисковиков, то она проста: быть очень нишевыми проектами с небольшой аудиторией, следовательно без ясных коммерческих перспектив или, наоборот, с полной ясностью их отсутствия.
Если посмотреть на примеры в статье, то видно, что такие поисковики либо специализируются в узкой, но востребованной нише, которая, возможно только пока, не выросла настолько, чтобы оказаться заметной на радарах Google или «Яндекса», либо тестируют оригинальную гипотезу в ранжировании, которая пока не применима в обычном поиске.
Например, если поиск по Tor вдруг окажется востребованным, то есть результаты оттуда понадобятся хотя бы проценту аудитории Google, то, конечно, обычные поисковики начнут решать проблему, как их найти и показать пользователю. Если поведение аудитории покажет, что заметной доле пользователей в заметном количестве запросов более релевантными кажутся результаты, данные без учёта факторов, зависящих от пользователя, то «Яндекс» или Google начнут давать такие результаты.
«Быть лучше» в контексте этой статьи не означает «быть лучше во всём». Да, во многих аспектах нашим героям далеко до и «Яндекса» (даже до Bing далековато). Но зато каждый из этих сервисов даёт пользователю нечто такое, чего не могут предложить гиганты поисковой индустрии. Наверняка вы тоже знаете подобные проекты. Поделитесь с нами - обсудим.