Jak przeprowadzane są wyszukiwania w wyszukiwarkach. Jak działają wyszukiwarki - fragmenty, algorytm wyszukiwania wstecznego, indeksowanie stron i funkcje Yandex
Witajcie drodzy czytelnicy!
Wyszukiwarki w globalnej przestrzeni internetowej w w tej chwili wystarczająco. Każda z nich ma własne algorytmy indeksowania i rankingowania witryn, ale generalnie zasada działania wyszukiwarek jest dość podobna.
Wiedza jak to działa system wyszukiwania w obliczu szybko rosnącej konkurencji stanowią istotną zaletę w promowaniu nie tylko komercyjnych, ale również informacyjnych serwisów i blogów. Ta wiedza pomaga zbudować skuteczną strategię optymalizacji strony internetowej i przy mniejszym wysiłku dostać się do TOP wyników wyszukiwania dla promowanych grup zapytań.
Zasady wyszukiwarki
Celem optymalizatora jest „dostosowanie” promowanych stron do algorytmów wyszukiwania, a tym samym pomoc tym stronom w osiągnięciu wysokich pozycji dla określonych zapytań. Jednak przed przystąpieniem do prac nad optymalizacją strony lub bloga konieczne jest przynajmniej powierzchowne zrozumienie cech pracy wyszukiwarek, aby zrozumieć, jak mogą one reagować na działania podejmowane przez optymalizator.
Oczywiście szczegółowe szczegóły dotyczące tworzenia wyników wyszukiwania to informacje, których wyszukiwarki nie ujawniają. Jednak do właściwych wysiłków wystarczy zrozumienie głównych zasad działania wyszukiwarek.
Metody wyszukiwania informacji
Dwie główne metody stosowane obecnie przez wyszukiwarki różnią się podejściem do wyszukiwania informacji.
- Algorytm wyszukiwania bezpośredniego, która polega na dopasowaniu każdego z dokumentów przechowywanych w bazie wyszukiwarki do frazy kluczowej (żądanie użytkownika), jest dość niezawodną metodą pozwalającą na znalezienie wszystkich potrzebnych informacji. Wadą tej metody jest to, że przy wyszukiwaniu w dużych tablicach danych czas potrzebny na znalezienie odpowiedzi jest dość duży.
- Algorytm odwrotnego indeksu, Kiedy fraza kluczowa porównywana jest lista dokumentów, w których jest obecny, jest to wygodne podczas interakcji z bazami danych zawierającymi dziesiątki i setki milionów stron. Dzięki takiemu podejściu wyszukiwanie odbywa się nie na wszystkich dokumentach, ale tylko na pliki specjalne, która zawiera listy słów zawartych na stronach witryny. Każdemu słowu na takiej liście towarzyszy wskazanie współrzędnych pozycji, w których ono występuje, oraz inne parametry. To właśnie ta metoda jest dziś używana w pracy tak znanych wyszukiwarek, jak Yandex i Google.
Należy tutaj zauważyć, że gdy użytkownik uzyskuje dostęp do paska wyszukiwania przeglądarki, wyszukiwanie nie odbywa się bezpośrednio w Internecie, ale w wstępnie zebranych, zapisanych i aktualnych ten moment bazy danych zawierające bloki informacji przetwarzanych przez wyszukiwarki (strony witryn). Szybkie generowanie wyników wyszukiwania jest możliwe dzięki pracy z indeksami odwrotnymi.

Treść tekstowa stron (indeksy bezpośrednie) jest również przechowywana przez wyszukiwarki i wykorzystywana do automatycznego generowania fragmentów tekstu z fragmentów tekstu, które są najbardziej odpowiednie dla zapytania.
Matematyczny model rankingu
W celu przyspieszenia wyszukiwania i uproszczenia procesu generowania zagadnienia najlepiej odpowiadającego żądaniu użytkownika stosowany jest pewien model matematyczny. Zadanie tego model matematyczny- znajdowanie żądane strony w aktualnej bazie indeksów odwrotnych, ocena ich stopnia zgodności z żądaniem i rozkład w kolejności malejącej istotności.
Samo znalezienie odpowiedniej frazy na stronie nie wystarczy. W przypadku określenia przez wyszukiwarki stosowane jest obliczenie wagi dokumentu w stosunku do żądania użytkownika. Dla każdego zapytania parametr ten jest wyliczany na podstawie następujących danych: częstotliwość użycia na analizowanej stronie oraz współczynnik, który odzwierciedla jak rzadko to samo słowo występuje w innych dokumentach bazy wyszukiwarki. Iloczyn tych dwóch wartości odpowiada wadze dokumentu.
Oczywiście przedstawiony algorytm jest bardzo uproszczony, ponieważ wyszukiwarki mają szereg innych dodatkowych współczynników wykorzystywanych w obliczeniach, ale znaczenie się nie zmienia. Im częściej pojedyncze słowożądania użytkownika występuje w dowolnym dokumencie, im wyższa jest waga tego ostatniego. Jednocześnie zawartość tekstowa strony jest uznawana za spam w przypadku przekroczenia określonych limitów, które są różne dla każdego żądania.
Główne funkcje wyszukiwarki
Wszystko istniejące systemy Wyszukiwarki są zaprojektowane do wykonywania kilku ważnych funkcji: wyszukiwania informacji, ich indeksowania, oceny jakości, prawidłowego rankingu i tworzenia wyników wyszukiwania. Podstawowym zadaniem każdej wyszukiwarki jest dostarczenie użytkownikowi poszukiwanych przez niego informacji, jak najdokładniejszej odpowiedzi na konkretne zapytanie.
Ponieważ większość użytkowników nie ma pojęcia, jak działają wyszukiwarki internetowe, możliwości edukacji użytkowników w zakresie „poprawnego” wyszukiwania są bardzo ograniczone (np. wskazówki wyszukiwania), programiści są zmuszeni do ulepszenia samego wyszukiwania. To ostatnie oznacza tworzenie algorytmów i zasad działania wyszukiwarek, które pozwalają znaleźć potrzebne informacje, niezależnie od tego, jak „poprawnie” są one sformułowane. wyszukiwana fraza.
Łów
Jest to śledzenie zmian w już zindeksowanych dokumentach i wyszukiwanie nowych stron, które mogą być prezentowane w wynikach wystawiania żądań użytkowników. Wyszukiwarki skanują zasoby w Internecie za pomocą wyspecjalizowanych programów zwanych pająkami lub robotami wyszukiwania.
Skanowanie zasobów internetowych i zbieranie danych jest wykonywane automatycznie przez boty wyszukujące. Po pierwszej wizycie na stronie i włączeniu jej do bazy wyszukiwarek, roboty zaczynają okresowo odwiedzać tę stronę w celu śledzenia i rejestrowania zmian, jakie zaszły w treści.
Ponieważ liczba rozwijających się zasobów w Internecie jest duża, a nowe witryny pojawiają się codziennie, opisany proces nie zatrzymuje się ani na minutę. Ta zasada działania wyszukiwarek w Internecie pozwala im mieć zawsze aktualne informacje o stronach dostępnych w sieci i ich zawartości.
Głównym zadaniem robota wyszukującego jest wyszukiwanie nowych danych i przesyłanie ich do wyszukiwarki w celu dalszego przetwarzania.

Indeksowanie
Wyszukiwarka jest w stanie znaleźć dane tylko o witrynach prezentowanych w jej bazie - innymi słowy zaindeksowanych. Na tym etapie wyszukiwarka musi określić, czy znalezione informacje należy wprowadzić do bazy danych, a jeśli tak, to w jakiej sekcji. Ten proces jest również wykonywany automatycznie.
Uważa się, że Google indeksuje prawie wszystkie informacje dostępne w sieci, podczas gdy Yandex podchodzi do indeksowania treści bardziej wybiórczo i nie tak szybko. Obaj giganci wyszukiwania Runetu działają na korzyść użytkownika, ale ogólne zasady praca wyszukiwarki Google i Yandex jest nieco inna, ponieważ opierają się one na unikalnych rozwiązaniach programowych, które składają się na każdy system.
Wspólnym punktem dla wyszukiwarek jest to, że proces indeksowania wszystkich nowych zasobów trwa dłużej niż indeksowanie nowej treści w witrynach znanych systemowi. Informacje, które pojawiają się w witrynach cieszących się dużym zaufaniem wyszukiwarek, trafiają do indeksu niemal natychmiast.
Nośny
Ranking to ocena przez algorytmy wyszukiwarek istotności indeksowanych danych i ich dopasowanie zgodnie z czynnikami charakterystycznymi dla tej wyszukiwarki. Otrzymane informacje są przetwarzane w celu wygenerowania wyników wyszukiwania dla całego zakresu zapytań użytkowników. Jakie informacje będą prezentowane w powyższych wynikach wyszukiwania, a co poniżej, jest całkowicie zdeterminowane sposobem działania wybranej wyszukiwarki i jej algorytmów.
Witryny znajdujące się w bazie wyszukiwarki są rozmieszczone według tematów i grup zapytań. Dla każdej grupy wniosków tworzona jest wstępna emisja, która podlega dalszej korekcie. Pozycje większości witryn zmieniają się po każdej aktualizacji emisji - aktualizowaniu rankingu, co dzieje się codziennie w Google, w wyszukiwarce Yandex - raz na kilka dni.
Człowiek jako pomocnik w walce o jakość emisji
Rzeczywistość jest taka, że nawet najbardziej zaawansowane wyszukiwarki, takie jak Yandex i Google, nadal potrzebują ludzkiej pomocy, aby generować wyniki spełniające przyjęte standardy jakości. Gdzie algorytm wyszukiwania nie działa wystarczająco dobrze, jego wyniki są dostosowywane ręcznie - oceniając zawartość strony pod kątem różnych kryteriów.
Liczna armia specjalnie przeszkolonych ludzi z różnych krajów– moderatorzy (oceniający) wyszukiwarek – każdego dnia muszą wykonać ogromną pracę, aby sprawdzić zgodność stron serwisu z żądaniami użytkowników, filtrując spam i niedozwolone treści (teksty, obrazy, filmy). Praca asesorów pozwala na uporządkowanie wydawania i przyczynia się do dalszego rozwoju samouczących się algorytmów wyszukiwania.

Wniosek
Wraz z rozwojem Internetu oraz stopniową zmianą standardów i form prezentacji treści zmienia się również podejście do wyszukiwania, usprawniane są procesy indeksowania i rankingowania informacji, stosowane algorytmy, pojawiają się nowe czynniki rankingowe. Wszystko to pozwala wyszukiwarkom na generowanie wyników najwyższej jakości i adekwatnych do żądań użytkowników, ale jednocześnie komplikuje życie webmasterom i specjalistom od promocji stron internetowych.
W komentarzach pod artykułem proponuję porozmawiać o tym, która z głównych wyszukiwarek Runetu - Yandex lub Google, Twoim zdaniem, działa lepiej, zapewniając użytkownikowi lepsze wyszukiwanie i dlaczego.
Dla wielu użytkowników Internet jest niezbędny do otrzymywania odpowiedzi na wpisywane przez nich zapytania (pytania).
Gdyby nie było wyszukiwarek, użytkownicy musieliby samodzielnie wyszukiwać potrzebne witryny, zapamiętywać je i spisywać. W wielu przypadkach znalezienie czegoś odpowiedniego „ręcznie” byłoby bardzo trudne, a często wręcz niemożliwe.
Dla nas cała ta rutyna polega na wyszukiwaniu, przechowywaniu i sortowaniu informacji w witrynach.
Zacznijmy od dobrze znanych wyszukiwarek Runetu.
Wyszukiwarki internetowe w języku rosyjskim
1) Zacznijmy od krajowej wyszukiwarki. Yandex pracuje nie tylko w Rosji, ale także pracuje na Białorusi i Kazachstanie, na Ukrainie, w Turcji. Jest też Yandex na język angielski.
2) Wyszukiwarka Google przyjechała do nas z Ameryki, ma rosyjskojęzyczną lokalizację:
3) Krajowa wyszukiwarka Mile ru, która jednocześnie reprezentuje sieć społecznościową VKontakte, Odnoklassniki, a także My World, słynny Answers Mail.ru i inne projekty.
4) Inteligentna wyszukiwarka
Nigma (Nigma) http://www.nigma.ru/
Od 19 września 2017 r. „intelektualna” nigma nie działa. Przestała być interesująca finansowo dla swoich twórców, przeszli na inną wyszukiwarkę o nazwie CocCoc.
5) Znana firma Rostelecom stworzyła wyszukiwarkę Sputnik.
Istnieje wyszukiwarka Sputnik, zaprojektowana specjalnie dla dzieci, o której pisałem.
6) Rambler był jedną z pierwszych krajowych wyszukiwarek:
Na świecie istnieją inne znane wyszukiwarki:
- bzdura,
- Wieśniak!
- Baidu,
- ekozja,
Spróbujmy dowiedzieć się, jak działa wyszukiwarka, czyli w jaki sposób są indeksowane witryny, analizowane są wyniki indeksowania i generowane są wyniki wyszukiwania. Zasady działania wyszukiwarek są w przybliżeniu takie same: wyszukiwanie informacji w Internecie, przechowywanie ich i sortowanie w celu wydania w odpowiedzi na żądania użytkowników. Ale algorytmy używane przez wyszukiwarki mogą być bardzo różne. Algorytmy te są utrzymywane w tajemnicy, a ich ujawnianie jest zabronione.
Wprowadzanie tego samego zapytania w szukaj ciągów różne wyszukiwarki, możesz uzyskać różne odpowiedzi. Powodem jest to, że wszystkie wyszukiwarki używają własnych algorytmów.
Cel wyszukiwarek
Przede wszystkim musisz wiedzieć, że wyszukiwarki to organizacje komercyjne. Ich celem jest osiągnięcie zysku. Zyski można zarobić z reklama kontekstowa, inne rodzaje reklamy, z promocją niezbędnych witryn do pierwszych wierszy wydania. Ogólnie jest wiele sposobów.
Zależy to od wielkości grupy odbiorców, to znaczy od tego, ile osób korzysta z tej wyszukiwarki. Im większa publiczność, tym więcej osób wyświetli reklamę. W związku z tym ta reklama będzie kosztować więcej. Wyszukiwarki mogą zwiększyć liczbę odbiorców o własna reklama, a także przyciąganie użytkowników poprzez poprawę jakości ich usług, algorytmu i wygody wyszukiwania.
Najważniejszą i najtrudniejszą rzeczą jest tutaj opracowanie w pełni funkcjonalnego algorytmu wyszukiwania, który zapewniłby odpowiednie wyniki dla większości zapytań użytkowników.
Praca wyszukiwarki i działania webmasterów
Każda wyszukiwarka ma swój własny algorytm, który musi uwzględniać ogromną liczbę różnych czynników podczas analizowania informacji i kompilowania wyników w odpowiedzi na żądanie użytkownika:
- wiek danej witryny,
- charakterystyka domeny witryny,
- jakość treści na stronie i jej rodzaje,
- funkcje nawigacji i struktury witryny,
- użyteczność (przyjazność dla użytkownika),
- czynniki behawioralne (wyszukiwarka może określić, czy użytkownik znalazł to, czego szukał w serwisie, czy też wrócił ponownie do wyszukiwarki i ponownie szuka tam odpowiedzi na to samo zapytanie)
- itp.
Wszystko to jest konieczne właśnie po to, aby wydanie na żądanie użytkownika było jak najbardziej adekwatne, zaspokajające potrzeby użytkownika. Jednocześnie algorytmy wyszukiwarek ciągle się zmieniają i ulepszają. Jak mówią, doskonałość nie ma granic.
Z drugiej strony webmasterzy i SEO nieustannie wymyślają nowe sposoby promowania swoich witryn, które nie zawsze są uczciwe. Zadaniem twórców algorytmu wyszukiwarki jest wprowadzenie w nim zmian, które nie pozwolą na pojawienie się w TOP „złych” stron nieuczciwych optymalizatorów.
Jak działa wyszukiwarka?
Teraz o tym, jak przebiega bezpośrednia praca wyszukiwarki. Składa się z co najmniej trzech etapów:
- łów,
- indeksowanie,
- nośny.
Liczba stron w Internecie jest po prostu astronomiczna. A każda strona to informacje, treści informacyjne, które są tworzone dla czytelników (prawdziwych ludzi).
Łów
Jest to roaming Internetu przez wyszukiwarkę w celu zbierania nowych informacji, analizowania linków i znajdowania nowych treści, które można wykorzystać do obsługi użytkownika w odpowiedzi na jego zapytania. Do skanowania wyszukiwarki mają specjalne roboty, które nazywane są robotami wyszukiwania lub pająkami.
Roboty wyszukiwania to programy, które automatycznie odwiedzają strony internetowe i zbierają z nich informacje. Indeksowanie może być podstawowe (robot po raz pierwszy odwiedza nową witrynę). Po wstępnym zebraniu informacji ze strony i wprowadzeniu ich do bazy wyszukiwarki, robot zaczyna odwiedzać jej strony z pewną regularnością. Jeśli nastąpiły jakieś zmiany (dodana nowa treść, usunięta stara treść), to wszystkie te zmiany zostaną naprawione przez wyszukiwarkę.
Głównym zadaniem pająka wyszukiwania jest znalezienie nowych informacji i przekazanie ich wyszukiwarce do kolejnego etapu przetwarzania, czyli indeksowania.
Indeksowanie
Wyszukiwarka może wyszukiwać informacje tylko wśród tych witryn, które są już zawarte w jej bazie (zaindeksowane przez nią). Jeżeli skanowanie jest procesem wyszukiwania i gromadzenia informacji, które są dostępne w danej witrynie, to indeksowanie jest procesem wprowadzania tych informacji do bazy danych wyszukiwarki. Na tym etapie wyszukiwarka automatycznie decyduje, czy wprowadzić tę lub inną informację do swojej bazy danych i gdzie je wprowadzić, w której sekcji bazy danych. Na przykład Google indeksuje prawie wszystkie informacje znalezione przez jego roboty w Internecie, podczas gdy Yandex jest bardziej wybredny i nie indeksuje wszystkiego.
W przypadku nowych witryn faza indeksowania może być długa, więc użytkownicy wyszukiwarek mogą długo czekać na nowe witryny. A Nowa informacja, który pojawia się na starych, promowanych witrynach, może zostać zaindeksowany niemal natychmiast i niemal od razu trafić do „indeksu”, czyli do bazy wyszukiwarek.
Nośny
Ranking to zestawienie informacji, które zostały wcześniej zaindeksowane i wprowadzone do bazy danych konkretnej wyszukiwarki, według rangi, czyli jakie informacje wyszukiwarka pokaże swoim użytkownikom w pierwszej kolejności, a jakie informacje zostaną umieszczone” ranga” niżej. Ranking może być przypisany do etapu obsługi przez wyszukiwarkę swojego klienta - użytkownika.
Na serwerach wyszukiwarki otrzymane informacje są przetwarzane i generowane jest zgłoszenie dla ogromnego zakresu wszelkiego rodzaju zapytań. W tym miejscu do gry wchodzą algorytmy wyszukiwarek. Wszystkie strony wymienione w bazie są pogrupowane tematycznie, tematy są podzielone na grupy zapytań. Dla każdej z grup wniosków można przygotować wstępne wydanie, które następnie zostanie skorygowane.
Dlaczego marketer powinien znać podstawowe zasady? optymalizacja wyszukiwarki? To proste: ruch organiczny jest świetnym źródłem napływającego strumienia grupa docelowa dla Twojej firmowej strony internetowej, a nawet stron docelowych.
Poznaj serię postów edukacyjnych na temat SEO.
Co to jest wyszukiwarka?
Wyszukiwarka jest duża baza dokumenty (treść). Roboty wyszukujące omijają zasoby i indeksują różne rodzaje treści, to właśnie te zapisane dokumenty są klasyfikowane w wyszukiwaniu.
W rzeczywistości Yandex to „obsada” Runetu (także Turcji i kilku stron anglojęzycznych), a Google to globalny Internet.
Indeks wyszukiwania to struktura danych zawierająca informacje o dokumentach i umiejscowieniu w nich słów kluczowych.
Zgodnie z zasadą działania wyszukiwarki są do siebie podobne, różnice tkwią w formułach rankingu (porządkowanie stron w wynikach wyszukiwania), które bazują na uczeniu maszynowym.
Każdego dnia miliony użytkowników przesyłają zapytania do wyszukiwarek.
„Streszczenie do napisania”:

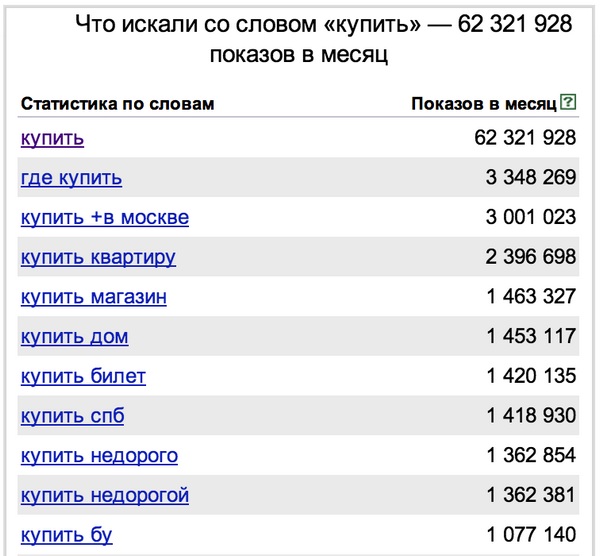
"Kup":
Ale najbardziej interesuje...

Jak zorganizowana jest wyszukiwarka?
Aby zapewnić użytkownikom szybkie odpowiedzi, architekturę wyszukiwania podzielono na 2 części:
- podstawowe szukanie,
- metawyszukiwanie.

Podstawowe szukanie
Wyszukiwanie podstawowe - program, który przeszukuje swoją część indeksu i dostarcza wszystkie dokumenty pasujące do zapytania.
Metasearch to program, który przetwarza zapytanie wyszukiwania, określa regionalność użytkownika, a jeśli zapytanie jest popularne, to daje gotową opcję wyszukiwania, a jeśli zapytanie jest nowe, wybiera wyszukiwanie podstawowe i wydaje polecenie wybierz dokumenty, a następnie uszereguj znalezione dokumenty za pomocą uczenia maszynowego i udostępnij użytkownikowi.

Klasyfikacja zapytań wyszukiwania
Aby udzielić użytkownikowi trafnej odpowiedzi, wyszukiwarka najpierw stara się zrozumieć, czego konkretnie potrzebuje. Zapytanie jest analizowane, a użytkownik jest analizowany równolegle.
Zapytania są analizowane według parametrów:
- Długość;
- definicja;
- popularność;
- konkurencyjność;
- składnia;
- geografia.
Typ wniosku:
- nawigacja;
- informacyjne;
- transakcyjne;
- multimedia;
- ogólny;
- urzędnik.
Po przeanalizowaniu i sklasyfikowaniu zapytania wybierana jest funkcja rankingu.

Oznaczenie typów żądań jest informacją poufną, a proponowane opcje są przypuszczeniami specjalistów ds. promocji w wyszukiwarkach.
Jeśli użytkownik ustawi ogólne zapytanie, wyszukiwarka zwróci różne rodzaje dokumenty. I należy rozumieć, że promując stronę komercyjną witryny w TOP-10 według ogólnej prośby, twierdzisz, że otrzymujesz nie jedno z 10 miejsc, ale liczbę miejsc
dla stron komercyjnych, co podkreśla formuła rankingu. I dlatego prawdopodobieństwo znalezienia się w czołówce dla takich żądań jest mniejsze.
Uczenie maszynowe MatrixNet to algorytm wprowadzony w 2009 roku przez Yandex, który wybiera funkcję rankingu dokumentów dla określonych zapytań.

MatrixNet jest używany nie tylko w wyszukiwarce Yandex, ale także w celach naukowych. Na przykład w Europejskim Centrum Badań Jądrowych jest używany do rzadkich zdarzeń w dużych ilościach danych (szukają bozonu Higgsa).
Dane pierwotne do oceny skuteczności formuły rankingowej zbiera dział asesorów. Są to specjalnie przeszkoleni ludzie, którzy oceniają próbkę miejsc według eksperymentalnego wzoru według następujących kryteriów.
Ocena jakości terenu
Vitalny - oficjalna strona (Sbierbank, LPgenerator). Zapytanie wyszukiwania odpowiada oficjalnej stronie internetowej, grupom w sieciach społecznościowych, informacjom o autorytatywnych zasobach.
Przydatne (ocena 5) - witryna udostępniająca na żądanie rozszerzone informacje.
Przykład - zapytanie: tkanina banerowa.
Witryna odpowiadająca ocenie „przydatne” powinna zawierać informacje:
- co to jest tkanina banerowa;
- specyfikacje;
- zdjęcia;
- rodzaje;
- cennik;
- coś innego.
Przykłady najczęstszych żądań:

Relevant+ (wynik 4) — ten wynik oznacza, że strona pasuje do wyszukiwanego hasła.
Odpowiednie (Wynik 3) — strona nie odpowiada dokładnie wyszukiwanemu hasłu.
Załóżmy, że wyszukiwanie hasła „Strażnicy Galaktyki” wyświetla stronę o filmie bez pokazów, stronę z poprzedniej sesji, stronę zwiastuna na youtube.
Nieistotne (Wynik 2) — strona nie pasuje do zapytania.
Przykład: nazwa hotelu wyświetla nazwę innego hotelu.
Aby promować zasób na żądanie ogólne lub informacyjne, musisz utworzyć stronę odpowiadającą ocenie „przydatne”.
W przypadku jasnych zapytań wystarczy osiągnąć wynik „odpowiednie+”.
Trafność uzyskuje się poprzez dopasowanie tekstu i linków strony do zapytań wyszukiwania.
wnioski
- Nie wszystkie zapytania mogą promować komercyjną stronę docelową;
- Nie wszystkie prośby o informacje mogą być wykorzystane do promowania witryny komercyjnej;
- Promując ogólne żądanie, utwórz przydatną stronę.
Częstym powodem, dla którego witryna nie dociera na szczyt, jest niezgodność treści promowanej strony z zapytaniem.
Porozmawiamy o tym w następnym artykule „Lista kontrolna podstawowej optymalizacji strony internetowej”.
Z definicji wyszukiwarka internetowa to system wyszukiwania informacji, który pomaga nam znaleźć informacje w: ogólnoświatowa sieć. Ułatwia to globalną wymianę informacji. Ale internet to nieustrukturyzowana baza danych. Rozwija się wykładniczo i stał się ogromnym repozytorium informacji. Znalezienie informacji w Internecie to trudne zadanie. Istnieje potrzeba posiadania narzędzia do zarządzania, filtrowania i wydobywania informacji o oceanach. Służy temu wyszukiwarka.
Jak działa wyszukiwarka?
Wyszukiwarki internetowe to wyszukiwarki, które wyszukują i pobierają informacje w Internecie. Większość z nich korzysta z architektury indeksowania przeszukiwacza. Zależą od ich modułów gąsienic. Roboty indeksujące, zwane również pająkami, to małe programy przemierzające strony internetowe.
Roboty indeksujące odwiedzają początkowy zestaw adresów URL. Wyszukują adresy URL, które pojawiają się na zindeksowanych stronach i wysyłają te informacje do modułu przeszukiwacza. Robot decyduje, które strony odwiedzić w następnej kolejności, i przekazuje te adresy URL robotom.
Tematy poruszane przez różne wyszukiwarki różnią się w zależności od używanych przez nie algorytmów. Niektóre wyszukiwarki są zaprogramowane do przeszukiwania witryn dla określonego tematu, podczas gdy inne roboty indeksujące mogą odwiedzać jak najwięcej miejsc.
Moduł indeksowania wyodrębnia informacje z każdej odwiedzanej strony i dodaje adres URL do bazy danych. Powoduje to powstanie ogromnej tabeli wyszukiwania z listy adresów URL wskazujących strony z informacjami. Tabela pokazuje strony, które zostały przeszukane podczas indeksowania.
Kolejnym ważnym elementem architektury wyszukiwarek jest moduł analizy. Tworzy indeks użyteczności. Narzędzie indeksujące może przyznać dostęp do stron o określonej długości lub stron zawierających określoną liczbę zdjęć.
Podczas procesu przeszukiwania i indeksowania wyszukiwarka zapisuje pobierane strony. Są one tymczasowo przechowywane w magazynie strony. Wyszukiwarki przechowują pamięć podręczną odwiedzanych stron, aby przyspieszyć wyszukiwanie już odwiedzonych stron.
Moduł zapytań wyszukiwarki otrzymuje zapytania od użytkowników w postaci słów kluczowych. Moduł rankingowy sortuje wyniki.
Architektura indeksatora przeszukiwacza ma wiele odmian. Zmieniają się w architektura rozproszona wyszukiwarka. Te architektury składają się z kolekcjonerów i brokerów. Kolektory zbierają informacje o indeksowaniu z serwerów internetowych, podczas gdy brokerzy zapewniają mechanizm indeksowania i interfejs zapytań. Brokerzy indeksują aktualizację na podstawie informacji otrzymanych od kolekcjonerów i innych brokerów. Mogą filtrować informacje. Wiele wyszukiwarek używa dziś tego typu architektury.
Wyszukiwarki i rankingi stron
Kiedy tworzymy zapytanie w wyszukiwarce, wyniki są wyświetlane w określonej kolejności. Większość z nas odwiedza strony z najwyższymi zamówieniami i ignoruje te ostatnie. Dzieje się tak, ponieważ uważamy, że kilka pierwszych stron jest bardziej odpowiednich dla naszego zapytania. Dlatego wszyscy są zainteresowani umieszczaniem swoich stron w pierwszej dziesiątce wyników wyszukiwania.
Słowa wymienione w interfejsie zapytań wyszukiwarki są słowami kluczowymi, których zażądały wyszukiwarki. To lista stron powiązanych z żądanymi słowami kluczowymi. Podczas tego procesu wyszukiwarki pobierają te strony, które mają wysoką liczbę wystąpień tych słów kluczowych. Szukają relacji między słowami kluczowymi. Uwzględniana jest również lokalizacja słów kluczowych, podobnie jak pozycja zawierającej je strony. Słowa kluczowe pojawiające się w tytułach stron lub adresach URL mają większą wagę. Strony, które prowadzą do nich linki, zwiększają ich popularność. Jeśli wiele innych witryn zawiera linki do strony, jest ona postrzegana jako wartościowa i bardziej trafna.
Istnieje algorytm rankingu, z którego korzysta każda wyszukiwarka. Algorytm to skomputeryzowana formuła zaprojektowana w celu dostarczania odpowiednich stron na żądanie użytkownika. Każda wyszukiwarka może mieć inny algorytm rankingowy, który analizuje strony w bazie danych wyszukiwarki w celu określenia odpowiednich odpowiedzi na zapytania wyszukiwania. Wyszukiwarki indeksują różne informacje na różne sposoby. Prowadzi to do tego, że dane zapytanie, dostarczone do dwóch różnych wyszukiwarek, może doprowadzić strony do: różne zamówienia lub wyciąg różne strony. Popularność strony internetowej to czynniki decydujące o trafności. Popularność strony po kliknięciu to kolejny czynnik decydujący o jej rankingu. Jest to miara tego, jak często odwiedzana jest witryna.
Webmasterzy próbują oszukać algorytmy wyszukiwarek, aby poprawić pozycję swojej witryny w SERPach. Wypełnianie stron witryny słowami kluczowymi lub używanie metatagów w celu oszukania strategii rankingowych w wyszukiwarkach. Ale wyszukiwarki są wystarczająco inteligentne! Udoskonalają swoje algorytmy, aby machinacje webmasterów nie wpływały na wyniki wyszukiwania.
Musisz zrozumieć, że nawet strony po kilku pierwszych na liście mogą zawierać dokładnie te informacje, których szukasz. Zapewniamy jednak, że dobre wyszukiwarki zawsze wyświetlają bardzo trafne strony w najwyższej kolejności!
Co to jest
DuckDuckGo to dość znana wyszukiwarka open source. kod źródłowy. Serwery znajdują się w USA. Oprócz własnego robota wyszukiwarka korzysta z wyników innych źródeł: Yahoo, Bing, Wikipedia.
Lepiej
DuckDuckGo pozycjonuje się jako najlepsze narzędzie do wyszukiwania prywatności i prywatności. System nie zbiera żadnych danych o użytkowniku, nie przechowuje logów (brak historii wyszukiwania), używa ciasteczka maksymalnie ograniczone.
DuckDuckGo nie zbiera ani nie udostępnia danych osobowych użytkowników. To jest nasza polityka prywatności.
Gabriel Weinberg, założyciel DuckDuckGo
Dlaczego tego potrzebujesz
Wszystkie główne wyszukiwarki próbują personalizować wyniki wyszukiwania na podstawie danych o osobie przed monitorem. Zjawisko to nazywa się „bańką filtra”: użytkownik widzi tylko te wyniki, które są zgodne z jego preferencjami lub które system uważa za takie.
Tworzy obiektywny obraz, który nie zależy od Twojego przeszłego zachowania w sieci i pozbywa się tematycznych reklam Google i Yandex w oparciu o Twoje prośby. DuckDuckGo ułatwia znalezienie informacji o języki obce, podczas gdy Google i Yandex domyślnie preferują witryny rosyjskojęzyczne, nawet jeśli zapytanie zostało wprowadzone w innym języku.

Co to jest
not Evil to system, który przeszukuje anonimową sieć Tor. Aby z niego skorzystać, musisz przejść do tej sieci, na przykład uruchamiając wyspecjalizowaną .
not Evil nie jest jedyną tego rodzaju wyszukiwarką. Jest LOOK (domyślne wyszukiwanie w przeglądarce Tor, dostępne ze zwykłego Internetu) lub TORCH (jedna z najstarszych wyszukiwarek w sieci Tor) i inne. Zdecydowaliśmy się na nie Zło z powodu niewątpliwej aluzji do Google (wystarczy spojrzeć na stronę startową).
Lepiej
Szukam tam gdzie google, „Yandex” i inne wyszukiwarki są z zasady zamknięte.
Dlaczego tego potrzebujesz
W sieci Tor jest wiele zasobów, których nie można znaleźć w przestrzegającym prawa Internecie. A ich liczba będzie rosła w miarę zacieśniania się kontroli władz nad zawartością sieci. Tor jest rodzajem sieci w Internecie z jej sieciami społecznościowymi, trackerami torrentów, mediami, rynkami, blogami, bibliotekami i tak dalej.
3. YaCy

Co to jest
YaCy to zdecentralizowana wyszukiwarka działająca na zasadzie sieci P2P. Każdy komputer, na którym zainstalowany jest główny moduł oprogramowania, samodzielnie skanuje Internet, czyli jest odpowiednikiem robota wyszukującego. Uzyskane wyniki są gromadzone we wspólnej bazie danych, z której korzystają wszyscy uczestnicy YaCy.
Lepiej
Trudno tu powiedzieć, czy jest lepiej, czy gorzej, ponieważ YaCy to zupełnie inne podejście do organizacji wyszukiwania. Brak jednego serwera i firmy właściciela sprawia, że wyniki są całkowicie niezależne od czyichkolwiek preferencji. Autonomia każdego węzła wyklucza cenzurę. YaCy jest w stanie przeszukiwać głębokie sieci i nieindeksowane sieci publiczne.
Dlaczego tego potrzebujesz
Jeśli jesteś zwolennikiem oprogramowania open source i darmowego Internetu, na który nie mają wpływu agencje rządowe i duże korporacje, to YaCy jest Twoim wyborem. Może być również używany do organizowania wyszukiwań w sieci firmowej lub innej sieci autonomicznej. I choć YaCy nie jest zbyt przydatny w życiu codziennym, jest godną alternatywą dla Google pod względem procesu wyszukiwania.
4. Pipl

Co to jest
Pipl to system przeznaczony do wyszukiwania informacji o konkretnej osobie.
Lepiej
Autorzy Pipl twierdzą, że ich wyspecjalizowane algorytmy wyszukują efektywniej niż „zwykłe” wyszukiwarki. W szczególności profile mają priorytet portale społecznościowe, komentarze, listy uczestników oraz różne bazy danych, w których publikowane są informacje o osobach, takie jak bazy orzeczeń sądowych. Wiodącą pozycję Pipl w tym obszarze potwierdzają Lifehacker.com, TechCrunch i inne publikacje.
Dlaczego tego potrzebujesz
Jeśli potrzebujesz znaleźć informacje o osobie mieszkającej w USA, to Pipl będzie znacznie skuteczniejszy niż Google. Najwyraźniej bazy danych rosyjskich sądów są niedostępne dla wyszukiwarki. Dlatego nie radzi sobie tak dobrze z obywatelami Rosji.

Co to jest
FindSounds to kolejna wyspecjalizowana wyszukiwarka. Przeszukuje otwarte źródła różnych dźwięków: dom, natura, samochody, ludzie i tak dalej. Usługa nie obsługuje żądań w języku rosyjskim, ale istnieje imponująca lista tagów w języku rosyjskim, które można wyszukiwać.
Lepiej
W wydawaniu tylko dźwięków i nic więcej. W ustawieniach możesz ustawić żądany format i jakość dźwięku. Wszystkie znalezione dźwięki są dostępne do pobrania. Istnieje wyszukiwanie wzorców.
Dlaczego tego potrzebujesz
Jeśli potrzebujesz szybko znaleźć dźwięk wystrzału z muszkietu, uderzenie ssącego dzięcioła lub krzyk Homera Simpsona, to ta usługa jest dla Ciebie. I wybraliśmy to tylko z dostępnych zapytań w języku rosyjskim. W języku angielskim spektrum jest jeszcze szersze.
Poważnie, wyspecjalizowana usługa oznacza wyspecjalizowaną grupę odbiorców. Ale czy tobie też się przyda?

Co to jest
Wolfram|Alpha to wyszukiwarka obliczeniowa. Zamiast linków do artykułów zawierających słowa kluczowe, daje gotową odpowiedź na żądanie użytkownika. Na przykład, jeśli wpiszesz „porównaj populację Nowego Jorku i San Francisco” w języku angielskim w formularzu wyszukiwania, Wolfram|Alpha natychmiast wyświetli tabele i wykresy z porównaniem.
Lepiej
Ta usługa jest lepsza niż inne w znajdowaniu faktów i obliczaniu danych. Wolfram|Alpha gromadzi i porządkuje dostępną w sieci wiedzę z różnych dziedzin, w tym nauki, kultury i rozrywki. Jeśli ta baza zawiera gotową odpowiedź na zapytanie, system ją pokazuje, jeśli nie, oblicza i wyświetla wynik. W tym przypadku użytkownik widzi tylko i nic więcej.
Dlaczego tego potrzebujesz
Jeśli jesteś na przykład studentem, analitykiem, dziennikarzem lub badaczem, możesz użyć Wolfram|Alpha do znalezienia i obliczenia danych związanych z Twoją działalnością. Usługa nie rozumie wszystkich próśb, ale stale się rozwija i staje się coraz inteligentniejsza.

Co to jest
Wyszukiwarka Dogpile wyświetla listę wyników z: wyniki wyszukiwania Google, Yahoo i inne popularne systemy.
Lepiej
Po pierwsze, Dogpile wyświetla mniej reklam. Po drugie, usługa wykorzystuje specjalny algorytm do wyszukiwania i wyświetlania najwyższe wyniki z różnych wyszukiwarek. Według twórców Dogpile, ich system generuje najbardziej kompletny problem w całym Internecie.
Dlaczego tego potrzebujesz
Jeśli nie możesz znaleźć informacji w Google lub innej standardowej wyszukiwarce, wyszukaj je w kilku wyszukiwarkach jednocześnie, używając Dogpile.

Co to jest
BoardReader to system wyszukiwania tekstu dla forów, serwisów Q&A i innych społeczności.
Lepiej
Usługa pozwala zawęzić pole wyszukiwania do serwisów społecznościowych. Dzięki specjalnym filtrom możesz szybko znaleźć posty i komentarze, które odpowiadają Twoim kryteriom: językowi, dacie publikacji, nazwie witryny.
Dlaczego tego potrzebujesz
BoardReader może przydać się specjalistom od PR i innym specjalistom od mediów, którzy są zainteresowani opinią mediów w określonych kwestiach.
Wreszcie
Życie alternatywnych wyszukiwarek jest często ulotne. Lifehacker zapytał byłego prezesa ukraińskiego oddziału firmy Yandex Siergieja Petrenko o długoterminowe perspektywy takich projektów.

Siergiej Petrenko
Były dyrektor generalny Yandex.Ukraine.
Jeśli chodzi o los alternatywnych wyszukiwarek, jest prosty: być bardzo niszowymi projektami z małą publicznością, a więc bez jasnych perspektyw komercyjnych lub, odwrotnie, z całkowitą jasnością ich braku.
Patrząc na przykłady w artykule, można zauważyć, że tego typu wyszukiwarki albo specjalizują się w wąskiej, ale poszukiwanej niszy, która chyba tylko do tej pory nie rozrosła się na tyle, by być zauważalnym na radarach Google czy Yandex. lub testują oryginalną hipotezę w rankingu, która nie ma jeszcze zastosowania w wyszukiwaniu konwencjonalnym.
Na przykład, jeśli nagle okaże się, że wyszukiwanie przez Tora jest poszukiwane, to znaczy, że przynajmniej procent odbiorców Google będzie potrzebować stamtąd wyników, wtedy oczywiście zwykłe wyszukiwarki zaczną rozwiązywać problem, jak znajdź je i pokaż użytkownikowi. Jeśli z zachowania odbiorców wynika, że znaczna część użytkowników w znacznej liczbie zapytań wydaje się bardziej trafnymi wynikami, danymi bez uwzględnienia czynników zależnych od użytkownika, to Yandex lub Google zaczną dawać takie wyniki.
„Być lepszym” w kontekście tego artykułu nie oznacza „być lepszym we wszystkim”. Tak, pod wieloma względami nasi bohaterowie są daleko od Yandex (nawet daleko od Binga). Ale każda z tych usług daje użytkownikowi coś, czego nie mogą zaoferować giganci branży wyszukiwania. Na pewno znasz też podobne projekty. Podziel się z nami - porozmawiajmy.