How to program neural networks. Fine tuning, create a neural network
Many of the terms in neural networks are related to biology, so let's start from the beginning:
The brain is a complex thing, but it can also be divided into several main parts and operations:
The causative agent may be internal(for example, an image or an idea):
Now let's look at the basic and simplified parts brain:
The brain is like a cable network.
Neuron- the main unit of calculation in the brain, it receives and processes the chemical signals of other neurons, and, depending on a number of factors, either does nothing or generates an electrical impulse, or Action Potential, which then sends signals to neighboring neurons through synapses related neurons:
Dreams, memories, self-regulating movements, reflexes, and indeed everything that you think or do - everything happens thanks to this process: millions, or even billions of neurons work at different levels and create connections that create various parallel subsystems and represent a biological neural network. net.
Of course, these are all simplifications and generalizations, but thanks to them we can describe a simple
neural network:
And describe it formalized using a graph:
Some explanation is required here. Circles are neurons, and lines are connections between them,
and, in order not to complicate at this stage, interconnections represent a direct flow of information from left to right. The first neuron in this moment active and highlighted in grey. We also assigned a number to it (1 if it works, 0 if it doesn't). Numbers between neurons show weight connections.
The graphs above show the time of the network, for a more accurate display, you need to divide it into time intervals:
To create your own neural network, you need to understand how weights affect neurons and how neurons learn. As an example, let's take a rabbit (test rabbit) and put it in the conditions of a classic experiment.
When a safe stream of air is directed at them, rabbits, like people, blink:
This behavior model can be drawn with graphs:
As in the previous diagram, these graphs show only the moment when the rabbit feels a breath, and we thus encode puff as a boolean value. In addition, we calculate whether the second neuron fires based on the value of the weight. If it is equal to 1, then the sensory neuron fires, we blink; if the weight is less than 1, we do not blink: the second neuron limit- 1.
Let's introduce one more element - safe sound signal:
We can model rabbit interest like this:
The main difference is that now the weight is zero, so we didn't get a blinking rabbit, well, not yet, at least. Now we will teach the rabbit to blink on command, mixing
irritants (beep and breath):
It is important that these events occur at different time era, in graphs it will look like this:
The sound itself does nothing, but the airflow still causes the rabbit to blink, and we show this through the weights times the stimuli (in red).
Education complex behavior can be simplified as a gradual change in weight between connected neurons over time.
To train a rabbit, repeat the steps:
For the first three attempts, the diagrams will look like this:
Please note that the weight for the sound stimulus increases after each repetition (highlighted in red), this value is now arbitrary - we chose 0.30, but the number can be anything, even negative. After the third repetition, you will not notice a change in the behavior of the rabbit, but after the fourth repetition, something amazing will happen - the behavior will change.
We removed the exposure to air, but the rabbit still blinks when it hears the beep! Our last schematic can explain this behavior:
We trained the rabbit to respond to sound by blinking.
In a real experiment of this kind, more than 60 repetitions may be required to achieve a result.
Now we will leave the biological world of the brain and rabbits and try to adapt everything that
learned to create an artificial neural network. First, let's try to do a simple task.
Let's say we have a machine with four buttons that dispenses food when the right one is pressed.
buttons (well, or energy if you are a robot). The task is to find out which button gives out a reward:
We can depict (schematically) what a button does when pressed like this:
It is better to solve such a problem as a whole, so let's look at all the possible results, including the correct one:
Click on the 3rd button to get your dinner.
To reproduce a neural network in code, we first need to make a model or graph that the network can be mapped to. Here is one suitable graph for the task, besides, it well displays its biological counterpart:
This neural network simply receives input - in this case it will be the perception of which button was pressed. Next, the network replaces the input information with weights and draws a conclusion based on the addition of the layer. It sounds a little confusing, but let's see how the button is represented in our model:
Note that all weights are 0, so the neural network, like a baby, is completely empty but fully interconnected.
Thus, we match an external event with the input layer of the neural network and calculate the value at its output. It may or may not coincide with reality, but we will ignore this for now and begin to describe the task in a way understandable to the computer. Let's start by entering the weights (we will use JavaScript):
Var inputs = ; var weights = ; // For convenience, these vectors can be called
The next step is to create a function that collects the input values and weights and calculates the output value:
Function evaluateNeuralNetwork(inputVector, weightVector)( var result = 0; inputVector.forEach(function(inputValue, weightIndex) ( layerValue = inputValue*weightVector; result += layerValue; )); return (result.toFixed(2)); ) / / May seem complex, but all it does is match the weight/input pairs and add the result
As expected, if we run this code, we will get the same result as in our model or graph…
EvaluateNeuralNetwork(inputs, weights); // 0.00
Live example: Neural Net 001.
The next step in improving our neural network will be a way to check its own output or resulting values comparably to the real situation,
let's first encode this particular reality into a variable:
To detect inconsistencies (and how many), we'll add an error function:
Error = Reality - Neural Net Output
With it, we can evaluate the performance of our neural network:
But more importantly - what about situations where reality gives a positive result?
Now we know that our neural network model doesn't work (and we know how), great! And this is great because now we can use the error function to control our training. But it all makes sense if we redefine the error function as follows:
error= Desired Output- Neural Net Output
A subtle yet important divergence, silently indicating that we will
use past results to compare with future actions
(and for learning, as we'll see later). It also exists in real life, complete
repetitive patterns, so it can become an evolutionary strategy (well, in
most cases).
var input = ; var weights = ; vardesiredResult = 1;
And a new function:
Function evaluateNeuralNetError(desired,actual) ( return (desired - actual); ) // After evaluating both the Network and the Error we would get: // "Neural Net output: 0.00 Error: 1"
Live example: Neural Net 002.
Let's summarize. We started with a task, made a simple model of it in the form of a biological neural network, and got a way to measure its performance compared to reality or the desired result. Now we need to find a way to correct the inconsistency - a process that for both computers and humans can be considered as learning.
How to train a neural network?
The basis of training both biological and artificial neural networks is repetition
And learning algorithms, so we will work with them separately. Let's start with
learning algorithms.
In nature, learning algorithms are understood as changes in physical or chemical
characteristics of neurons after the experiments:
The dramatic illustration of how two neurons change over time in the code and our "learning algorithm" model means that we will just change things over time to make our lives easier. So let's add a variable to indicate how much easier life is:
Var learningRate = 0.20; // The larger the value, the faster the learning process will be :)
And what will it change?
This will change the weights (just like a rabbit!), especially the weight of the output we want to get:
How to code such an algorithm is your choice, for simplicity I add the learning factor to the weight, here it is in the form of a function:
Function learn(inputVector, weightVector) ( weightVector.forEach(function(weight, index, weights) ( if (inputVector > 0) ( weights = weight + learningRate; ) )); )
When used, this training function will simply add our learning rate to the weight vector active neuron, before and after the training circle (or repetition), the results will be as follows:
// Original weight vector: // Neural Net output: 0.00 Error: 1 learn(input, weights); // New Weight vector: // Neural Net output: 0.20 Error: 0.8 // If it's not obvious, the output of the neural network is close to 1 (chicken output) - which is what we wanted, so we can conclude that we are moving in right direction
Live example: Neural Net 003.
Okay, now that we are moving in the right direction, the last piece of this puzzle will be the implementation repetitions.
It's not that hard, in nature we just do the same thing over and over again, but in code we just specify the number of repetitions:
Var trials = 6;
And the introduction of the number of repetitions function into our training neural network will look like this:
Function train(trials) ( for (i = 0; i< trials; i++) {
neuralNetResult = evaluateNeuralNetwork(input, weights);
learn(input, weights);
}
}
And here is our final report:
Neural Net output: 0.00 Error: 1.00 Weight Vector: Neural Net output: 0.20 Error: 0.80 Weight Vector: Neural Net output: 0.40 Error: 0.60 Weight Vector: Neural Net output: 0.60 Error: 0.40 Weight Vector: Neural Net output: 0.80 Error : 0.20 Weight Vector: Neural Net output: 1.00 Error: 0.00 Weight Vector: // Chicken Dinner !
Live example: Neural Net 004.
Now we have a weight vector that will only give one result (chicken for dinner) if the input vector matches reality (pressing the third button).
So what's the cool thing we just did?
In this particular case, our neural network (after training) can recognize the input and say what will lead to the desired result (we will still need to program specific situations):
In addition, it is a scalable model, a toy and a tool for our learning with you. We were able to learn something new about machine learning, neural networks and artificial intelligence.
Caution to users:
- The mechanism for storing the learned weights is not provided, so this neural network will forget everything it knows. When updating or rerunning the code, you need at least six successful repetitions for the network to fully train if you think that a person or a machine will press the buttons in a random order ... This will take some time.
- Biological networks for learning important things have a learning rate of 1, so only one successful repetition will be needed.
- There is a learning algorithm that is very similar to biological neurons, it has a catchy name: widroff-hoff rule, or widroff-hoff training.
- Neuron thresholds (1 in our example) and retraining effects (when in large numbers repetitions will result in more than 1) are not taken into account, but they are very important in nature and are responsible for large and complex blocks of behavioral responses. So are negative weights.
Notes and bibliography for further reading
I tried to avoid the math and the strict terms, but in case you're wondering, we built a perceptron, which is defined as a supervised learning algorithm (supervised learning) of dual classifiers - heavy stuff.The biological structure of the brain is not an easy topic, partly because of inaccuracies, partly because of its complexity. Better to start with Neuroscience (Purves) and Cognitive Neuroscience (Gazzaniga). I modified and adapted the rabbit example from Gateway to Memory (Gluck), which is also a great guide to the world of graphs.
Another awesome resource, An Introduction to Neural Networks (Gurney), is great for all your AI needs.
And now in Python! Thanks to Ilya Andshmidt for providing the Python version:
Inputs = weights = desired_result = 1 learning_rate = 0.2 trials = 6 def evaluate_neural_network(input_array, weight_array): result = 0 for i in range(len(input_array)): layer_value = input_array[i] * weight_array[i] result += layer_value print("evaluate_neural_network: " + str(result)) print("weights: " + str(weights)) return result def evaluate_error(desired, actual): error = desired - actual print("evaluate_error: " + str(error) ) return error def learn(input_array, weight_array): print("learning...") for i in range(len(input_array)): if input_array[i] > 0: weight_array[i] += learning_rate def train(trials ): for i in range(trials): neural_net_result = evaluate_neural_network(inputs, weights) learn(inputs, weights) train(trials)
And now on GO! Credit to Kieran Maher for this version.
Package main import ("fmt" "math") func main() ( fmt.Println("Creating inputs and weights ...") inputs:= float64(0.00, 0.00, 1.00, 0.00) weights:= float64(0.00, 0.00, 0.00, 0.00) desired:= 1.00 learningRate:= 0.20 trials:= 6 train(trials, inputs, weights, desired, learningRate) ) func train(trials int, inputs float64, weights float64, desired float64, learningRate float64) ( for i:= 1;i< trials; i++ { weights = learn(inputs, weights, learningRate) output:= evaluate(inputs, weights) errorResult:= evaluateError(desired, output) fmt.Print("Output: ") fmt.Print(math.Round(output*100) / 100) fmt.Print("\nError: ") fmt.Print(math.Round(errorResult*100) / 100) fmt.Print("\n\n") } } func learn(inputVector float64, weightVector float64, learningRate float64) float64 { for index, inputValue:= range inputVector { if inputValue >0.00 ( weightVector = weightVector + learningRate ) ) return weightVector ) func evaluate(inputVector float64, weightVector float64) float64 ( result:= 0.00 for index, inputValue:= range inputVector ( layerValue:= inputValue * weightVector result = result + layerValue ) return result ) func evaluateError(desired float64, actual float64) float64 ( return desired - actual )
You can help and transfer some funds for the development of the site
An artificial neural network is a collection of neurons that interact with each other. They are able to receive, process and create data. It is as difficult to imagine as the work of the human brain. The neural network in our brain is working so that you can now read this: our neurons recognize the letters and put them into words.
An artificial neural network is like a brain. It was originally programmed to simplify some complex computing processes. Today, neural networks have much more possibilities. Some of them are on your smartphone. Another part has already recorded in its database that you opened this article. How all this happens and why, read on.
How it all started
People really wanted to understand where a person's mind comes from and how the brain works. In the middle of the last century, Canadian neuropsychologist Donald Hebb understood this. Hebb studied the interaction of neurons with each other, investigated the principle by which they are combined into groups (scientifically - ensembles) and proposed the first algorithm in science for training neural networks.
A few years later, a group of American scientists modeled an artificial neural network that could distinguish square shapes from other shapes.
How does a neural network work?
The researchers found that a neural network is a collection of layers of neurons, each of which is responsible for recognizing a specific criterion: shape, color, size, texture, sound, volume, etc. Year after year, as a result of millions of experiments and tons of calculations to the simplest network more and more layers of neurons were added. They take turns working. For example, the first determines whether a square is or is not a square, the second understands whether the square is red or not, the third calculates the size of the square, and so on. Not squares, not red and wrong size figures fall into new groups of neurons and are examined by them.
What are neural networks and what can they do?
Scientists have developed neural networks so that they have learned to distinguish between complex images, videos, texts and speech. There are a lot of types of neural networks today. They are classified depending on the architecture - sets of data parameters and the weight of these parameters, a certain priority. Below are some of them.
Convolutional Neural Networks
Neurons are divided into groups, each group calculates the characteristic given to it. In 1993, French scientist Jan LeCun showed the world LeNet 1, the first convolutional neural network that could quickly and accurately recognize numbers written on paper by hand. See for yourself:
Today, convolutional neural networks are used mainly for multimedia purposes: they work with graphics, audio and video.
Recurrent neural networks
Neurons consistently remember information and build further actions based on this data. In 1997, German scientists modified the simplest recurrent networks to networks with a long short-term memory. Based on them, networks with controlled recurrent neurons were then developed.
Today, with the help of such networks, texts are written and translated, bots are programmed that conduct meaningful dialogues with a person, codes for pages and programs are created.
The use of this kind of neural networks is the ability to analyze and generate data, compile databases and even make predictions.
In 2015, SwiftKey released the world's first keyboard powered by a recurrent neural network with controlled neurons. Then the system gave hints in the process of typing based on the last words entered. Last year, the developers trained the neural network to learn the context of the typed text, and the hints became meaningful and useful:

Combined neural networks (convolutional + recurrent)
Such neural networks are able to understand what is in the image and describe it. And vice versa: draw images according to the description. The clearest example was demonstrated by Kyle Macdonald, who took a neural network for a walk around Amsterdam. The network instantly determined what was in front of it. And almost always exactly:

Neural networks are constantly self-learning. Through this process:
1. Skype has introduced the possibility of simultaneous translation for 10 languages. Among which, for a moment, there are Russian and Japanese - one of the most difficult in the world. Of course, the quality of the translation needs serious improvement, but the very fact that even now you can communicate with colleagues from Japan in Russian and be sure that you will be understood is inspiring.
2. Yandex created two search algorithms based on neural networks: Palekh and Korolev. The first one helped to find the most relevant sites for low-frequency queries. "Palekh" studied the titles of the pages and compared their meaning with the meaning of requests. On the basis of Palekh, Korolev appeared. This algorithm evaluates not only the title, but also the entire text content of the page. The search is becoming more accurate, and site owners are starting to approach the content of the pages more intelligently.
3. Colleagues of SEO specialists from Yandex have created a musical neural network: it composes poetry and writes music. The neurogroup is symbolically called Neurona, and they already have their first album:

4. Google Inbox uses neural networks to respond to a message. Technology development is in full swing, and today the network is already studying correspondence and generating possible options response. You can not waste time typing and not be afraid to forget some important agreement.

5. YouTube uses neural networks to rank videos, and according to two principles at once: one neural network studies videos and audience reactions to them, the other conducts research on users and their preferences. That is why YouTube recommendations are always on topic.
6. Facebook is actively working on DeepText AI - a communication program that understands jargon and cleans chats from obscene vocabulary.
7. Applications like Prisma and Fabby, built on neural networks, create images and videos:

Colorize restores color to black and white photos (surprise grandma!).

MakeUp Plus selects the perfect lipstick for girls from a real range of real brands: Bobbi Brown, Clinique, Lancome and YSL are already in business.

8.
Apple and Microsoft are constantly upgrading their neural Siri and Contana. So far, they are only following our orders, but in the near future they will begin to take the initiative: to give recommendations and anticipate our desires.
And what else awaits us in the future?
Self-learning neural networks can replace people: they will start with copywriters and proofreaders. Already, robots create texts with meaning and without errors. And they do it much faster than people. They will continue with employees of call centers, technical support, moderators and administrators of publics in social networks. Neural networks already know how to learn the script and reproduce it by voice. What about in other areas?
Agricultural sector
The neural network will be implemented in special equipment. Combines will autopilot, scan plants and study the soil, transmitting data to the neural network. She will decide - to water, fertilize or spray from pests. Instead of a couple of dozen workers, two specialists will be needed at most: a supervisory and a technical one.
The medicine
Microsoft is now actively working on the creation of a cure for cancer. Scientists are engaged in bioprogramming - they are trying to digitize the process of the emergence and development of tumors. When everything works out, programmers will be able to find a way to block such a process, by analogy, a medicine will be created.
Marketing
Marketing is highly personalized. Already, neural networks can determine in seconds which user, what content and at what price to show. In the future, the participation of the marketer in the process will be reduced to a minimum: neural networks will predict requests based on data about user behavior, scan the market and issue the most suitable offers by the time a person thinks about buying.
E-commerce
Ecommerce will be implemented everywhere. You no longer need to go to the online store using the link: you can buy everything where you see it in one click. For example, you are reading this article a few years later. You really like the lipstick on the screen from the MakeUp Plus app (see above). You click on it and go straight to the cart. Or watch a video about latest model Hololens (Mixed Reality Glasses) and place an order right from YouTube.
In almost every field, specialists with knowledge or at least an understanding of the structure of neural networks, machine learning and systems will be valued. artificial intelligence. We will exist side by side with robots. And the more we know about them, the calmer we will live.
P.S. Zinaida Falls is a Yandex neural network that writes poetry. Rate the work that the machine wrote, having learned on Mayakovsky (spelling and punctuation preserved):
« This»
this
just
something
in future
and power
that person
is there everything or not
it's blood all around
deal
getting fat
glory at
land
with a crack in the beak
Impressive, right?
Recently, more and more often they talk about the so-called neural networks, they say, soon they will be actively used in robotics, and in mechanical engineering, and in many other areas of human activity, but the algorithms of search engines, the same Google, are already slowly starting to use them. work. What are these neural networks, how do they work, what are their applications and how they can be useful for us, read about all this further.
What are neural networks
Neural networks are one of the areas scientific research in the field of creating artificial intelligence (AI), which is based on the desire to imitate the human nervous system. Including her (nervous system) ability to correct mistakes and self-learn. All this, although somewhat rough, should allow us to simulate the work of the human brain.
Biological neural networks
But this definition in the paragraph above is purely technical, but speaking in the language of biology, the neural network is the human nervous system, that set of neurons in our brain, thanks to which we think, make certain decisions, perceive the world around us.
A biological neuron is a special cell consisting of a nucleus, a body, and processes, moreover, having a close relationship with thousands of other neurons. Through this connection, electrochemical impulses are constantly transmitted, bringing the entire neural network into a state of excitement or vice versa. For example, some pleasant and at the same time exciting event (meeting a loved one, winning a competition, etc.) will generate an electrochemical impulse in the neural network that is located in our head, which will lead to its excitation. As a result, the neural network in our brain will transmit its excitation to other organs of our body and will lead to increased heart rate, more frequent blinking of the eyes, etc.
Here in the picture is a highly simplified model of the biological neural network of the brain. We see that a neuron consists of a cell body and a nucleus, the cell body, in turn, has many branched fibers called dendrites. Long dendrites are called axons and have a length much greater than shown in this figure, through axons communication between neurons is carried out, thanks to them the biological neural network works in our heads.
History of neural networks
What is the history of the development of neural networks in science and technology? It originates with the advent of the first computers or computers (electronic computers) as they were called in those days. So back in the late 1940s, a certain Donald Hebb developed a neural network mechanism, which laid down the rules for teaching computers, these “protocomputers”.
The further chronology of events was as follows:
- In 1954, the first practical use neural networks in the work of computers.
- In 1958, Frank Rosenblatt developed an algorithm for pattern recognition and a mathematical annotation for it.
- In the 1960s, interest in the development of neural networks faded somewhat due to the weak computing power of that time.
- And it was revived again already in the 1980s, it was during this period that a system with a feedback mechanism appeared, self-learning algorithms were developed.
- By 2000, the power of computers had grown so much that they were able to realize the wildest dreams of scientists of the past. At this time, programs for voice recognition, computer vision and much more appeared.

Artificial neural networks
Artificial neural networks are commonly understood as computing systems having the ability to self-learning, gradually increasing their productivity. The main elements of the neural network structure are:
- Artificial neurons, which are elementary interconnected units.
- is a connection that is used to send and receive information between neurons.
- A signal is the actual information to be transmitted.
Application of neural networks
The scope of artificial neural networks is expanding every year, today they are used in such areas as:
- Machine learning is a type of artificial intelligence. It is based on AI training on the example of millions of tasks of the same type. Nowadays, machine learning is actively implemented search engines Google, Yandex, Bing, Baidu. So based on millions search queries, which we all type into Google every day, their algorithms learn to show us the most relevant results so that we can find exactly what we are looking for.
- In robotics, neural networks are used in the development of numerous algorithms for the iron "brains" of robots.
- Architects computer systems use neural networks to solve the problem of parallel computing.
- With the help of neural networks, mathematicians can solve various complex mathematical problems.
Types of Neural Networks
In general, for various tasks are used different kinds and types of neural networks, among which are:
- convolutional Neural Networks,
- recurrent neural networks,
- Hopfield neural network.

Convolutional Neural Networks
Convolutional networks are one of the most popular types of artificial neural networks. So they proved their effectiveness in visual pattern recognition (video and images), recommender systems and language processing.
- Convolutional neural networks are highly scalable and can be used for pattern recognition of any large resolution.
- These networks use volumetric three-dimensional neurons. Within one layer, neurons are connected only by a small field, called the receptive layer.
- The neurons of neighboring layers are connected through the mechanism of spatial localization. The work of many such layers is provided by special non-linear filters that respond to an increasing number of pixels.
Recurrent Neural Networks
Such neural networks are called recurrent, the connections between the neurons of which form an indicative cycle. Has the following characteristics:
- Each connection has its own weight, which is also a priority.
- Nodes are divided into two types, introductory nodes and hidden nodes.
- Information in a recurrent neural network is transmitted not only in a straight line, layer by layer, but also between the neurons themselves.
- An important distinguishing feature of a recurrent neural network is the presence of the so-called "area of attention", when the machine can be given certain pieces of data that require enhanced processing.
Recurrent neural networks are used in the recognition and processing of text data (in frequency, they are based on Google translator, the Yandex Palekh algorithm, voice assistant Apple Siri).
Neural networks, video
And in conclusion interesting video about neural networks.

When writing the article, I tried to make it as interesting, useful and of high quality as possible. I will be grateful for any feedback and constructive criticism in the form of comments to the article. You can also write your wish / question / suggestion to my mail [email protected] or on Facebook, with respect, the author.
This time I decided to study neural networks. I was able to get basic skills in this matter during the summer and autumn of 2015. By basic skills, I mean that I can create a simple neural network myself from scratch. You can find examples in my GitHub repositories. In this article, I will give some clarifications and share resources that you may find useful for your study.
Step 1: Neurons and Feedforward Propagation
So what is a "neural network"? Let's wait with this and deal with one neuron first.
A neuron is like a function: it accepts multiple inputs and returns one.
The circle below represents an artificial neuron. It receives 5 and returns 1. The input is the sum of the three synapses connected to the neuron (three arrows on the left).
On the left side of the picture we see 2 input values (in green) and an offset (highlighted in brown).
The input data can be numerical representations of two different properties. For example, when creating a spam filter, they could mean having more than one word written in CAPITAL LETTERS and having the word "Viagra".
The input values are multiplied by their so-called "weights", 7 and 3 (highlighted in blue).
Now we add the resulting values with the offset and get a number, in our case 5 (highlighted in red). This is the input of our artificial neuron.

Then the neuron performs some kind of calculation and produces an output value. We got 1 because the rounded value of the sigmoid at point 5 is 1 (more on this function later).
If this were a spam filter, the fact that the output is 1 would mean that the text was marked as spam by the neuron.

Neural network illustration from Wikipedia.
If you combine these neurons, you get a forward-propagating neural network - the process goes from input to output, through neurons connected by synapses, as in the picture on the left.
Step 2. Sigmoid
After you've watched the Welch Labs tutorials, it's a good idea to check out the fourth week of the Coursera machine learning course on neural networks to help you understand how they work. The course goes deep into math and is based on Octave, while my preference is Python. Because of this, I skipped the exercises and gleaned everything necessary knowledge from video.

Sigmoid simply maps your value (on the horizontal axis) to a segment from 0 to 1.
The first priority for me was to study the sigmoid, as it figured in many aspects of neural networks. I already knew something about her from the third week of the above course, so I reviewed the video from there.
But videos alone won't take you far. For a complete understanding, I decided to code it myself. So I started writing an implementation of the logistic regression algorithm (which uses sigmoid).
It took a whole day, and the result is unlikely to be satisfactory. But it doesn't matter, because I figured out how everything works. The code can be seen.
You don't have to do it yourself, because it requires special knowledge - the main thing is that you understand how the sigmoid works.
Step 3 Back Propagation Method
Understanding how a neural network works from input to output is not that difficult. It is much more difficult to understand how a neural network is trained on datasets. The principle I used is called
James Loy, Georgia Tech University. A guide for beginners, after which you can create your own neural network in Python.
Motivation: focusing on personal experience in learning deep learning, I decided to create a neural network from scratch without complex educational library, such as, for example, . I believe that it is important for a novice Data Scientist to understand internal structure neural network.
This article contains what I have learned and I hope it will be useful for you too! Other useful related articles:
What is a neural network?
Most articles on neural networks draw parallels with the brain when describing them. I find it easier to describe neural networks as a mathematical function that maps a given input to a desired output without going into too much detail.
Neural networks consist of the following components:
- input layer, x
- arbitrary amount hidden layers
- output layer, ŷ
- kit scales And offsets between each layer W And b
- choice activation functions for each hidden layer σ ; in this work, we will use the Sigmoid activation function
The diagram below shows the architecture of a two-layer neural network (note that the input layer is usually excluded when counting the number of layers in a neural network).
Creating a Neural Network class in Python looks simple:
Neural network training
Output ŷ simple two layer neural network:
In the equation above, the weights W and the biases b are the only variables that affect the output ŷ.
Naturally, the correct values for the weights and biases determine the accuracy of the predictions. The process of fine-tuning the weights and biases from the input is known as neural network training.
Each iteration of the learning process consists of the following steps
- calculating the predicted output ŷ, called forward propagation
- updating weights and biases, called backpropagation
The sequence chart below illustrates the process:

direct propagation
As we saw in the graph above, forward propagation - is just a simple calculation, and for a basic 2-layer neural network, the output of the neural network is given by:
Let's add a forward propagation function to our Python code to do this. Note that for simplicity, we have assumed that offsets are 0.
However, we need a way to evaluate the “quality factor” of our forecasts, that is, how far our forecasts are.) Loss function just allows us to do this.
Loss function
There are many loss functions available, and the nature of our problem should dictate our choice of loss function. In this work, we will use sum of squared errors as a loss function.

The sum of squared errors - is the average of the difference between each predicted and actual value.
The learning goal is to find a set of weights and biases that minimizes the loss function.
backpropagation
Now that we have measured our prediction error (loss), we need to find a way propagating the error back and update our weights and biases.
In order to know the appropriate sum to adjust the weights and biases, we need to know the derivative of the loss function with respect to the weights and biases.
Recall from the analysis that the derivative of the - function is the tangent of the slope of the function.

If we have a derivative, then we can simply update the weights and biases by increasing/decreasing them (see diagram above). It is called gradient descent.
However, we cannot directly calculate the derivative of the loss function with respect to weights and biases, since the loss function equation does not contain weights and biases. So we need a chain rule to help with the calculation.
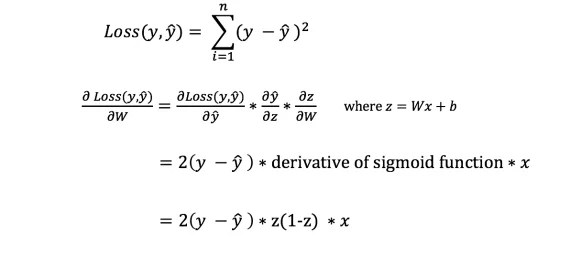
Phew! This was cumbersome, but allowed us to get what we need - the derivative (slope) of the loss function with respect to the weights. Now we can adjust the weights accordingly.
Let's add the backpropagation (backpropagation) function to our Python code:
Checking the operation of the neural network
Now that we have our complete Python code for doing forward and back propagation, let's take our neural network as an example and see how it works.
 Ideal set of scales
Ideal set of scales Our neural network needs to learn the ideal set of weights to represent this feature.
Let's train a neural network for 1500 iterations and see what happens. Looking at the iteration loss plot below, we can clearly see that the loss is decreasing monotonically to a minimum. This is consistent with the gradient descent algorithm we talked about earlier.

Let's look at the final prediction (inference) from the neural network after 1500 iterations.

We did it! Our forward and back propagation algorithm showed successful work neural network, and the predictions converge on the true values.
Note that there is a slight difference between the predictions and the actual values. This is desirable as it prevents overfitting and allows the neural network to generalize better on unseen data.
Final thoughts
I learned a lot in the process of writing my own neural network from scratch. While deep learning libraries such as TensorFlow and Keras allow for the creation of deep networks without fully understanding inner work neural networks, I find it helpful for beginning Data Scientists to get a deeper understanding of them.
I have invested a lot of my personal time in this work and I hope you find it useful!